
Databricks and the Future of Data
A Case Study on Riding S Curves: Past, Present, and Future of the Data & AI Company

For a bit of Generative Value lore, I wrote my first Databricks Deep Dive in March of 2023. At the time, this was just my personal investment journal and had 30 subscribers (I checked!)
Somehow, the team at Databricks got a hold of it, and Ali Ghodsi shared it on LinkedIn. The internet’s a funny place. (Ali/Ali’s team, do let me know if you want to come on for an interview.)
Now, the opportunity to write about Databricks has come up again. The last three articles of mine have formed a semi-intentional series on the lifecycle of industries. As WB says,”The boat you’re in matters much more than how hard you’re rowing.”
As a bookend on this series, I wanted to write a deep dive on one of my favorite companies that exemplifies riding the SaaS -> AI S curve. Databricks is as good of an example as there is.

Let’s start at the beginning.
The History of Databricks
The Netflix Prize
Sometimes stories write themselves, and Databricks has this incredible founding story that does so.
So in 2006, Netflix announces a $1M competition called the “The Netflix Prize” for anyone who improves their recommendation algorithm by 10%.
For some context at this time, the rise of the internet led to the proliferation of big data and unstructured data. Companies were exploring how to best leverage this data. To do so, companies needed to store data, write algorithms, and run those algorithms on that data (which requires huge amounts of computing power). The predominant technology at the time was Hadoop, released in 2006. Hadoop, however, was too inefficient and difficult to use to be effective in this new age of big data:

So, Netflix needs a more efficient way to run this process. By 2009, 50k participants had entered the contest, but no one had quite met the 10% improvement requirement. The dataset included all of these movies (18k+), all of these ratings (100M+), and all of this user data (450k users). Millions
A Berkeley Ph.D. student named Lester Mackey had decided to compete in the contest. He faced a clear problem: there was no tool to efficiently run algorithms on that large of a data set.
Matei Zaharia, a classmate (and now a legend in data), built a tool to more efficiently process algorithms. That tool would go on to become Spark.
Mackey uses this tool from Zaharia to iterate over the dataset and get the 10% improvement Netflix had been hunting for. Unfortunately, their submission was 20 minutes past the deadline, and a team out of AT&T won the prize (feels timely to add in some old adage about the turtle and the hare).
The Rise of Spark and the Founding of Databricks
At this point, Zahari had seen issues with big data processing while at Yahoo and knew the shortcomings of Hadoop as an early contributor. He decides to team up with fellow academics at the Berkeley AMPLab to build out Spark and commercialize it via Databricks.

The early vision for Databricks is articulated remarkably similar to today: one unified platform for analytics with the goal of enabling artifical intelligence.
Let’s take a step back: why does Databricks need to exist in the first place? That comes down to two questions:
1. Why does Spark need to exist?
Processing big data is really hard at this time and it’s going to keep getting harder. If companies want to be able to glean information from large amounts of data, a tool like Spark needs to exist. Tailwind #1: Big Data.
2. Why does Databricks need to exist?
Secondly, the Databricks team knew managing big data was only going to get harder. The cloud fundamentally unlocked the ability to scale compute and storage separately, AND HAVE VIRTUALLY UNLIMITED AMOUNTS OF BOTH. Open-source can be really hard to manage, so Databricks offers the power of Spark and the ease of use of managed cloud software. Tailwind #2: The Cloud.
Databricks even turned down a $20M offer from a financial services firm to offer Databricks on-prem…when it had only $10M in revenue.

They articulate Databricks as a tool to “make simple things easy” and “make complex things possible.” Put simply, Spark allows large compute workloads to be run faster and more cost-effectively than Hadoop. A Spark driver takes the program written by the user and distributes the tasks that need to be executed. The Cluster Manager allocates the necessary resources to accomplish the task, and the executors process the tasks accordingly.
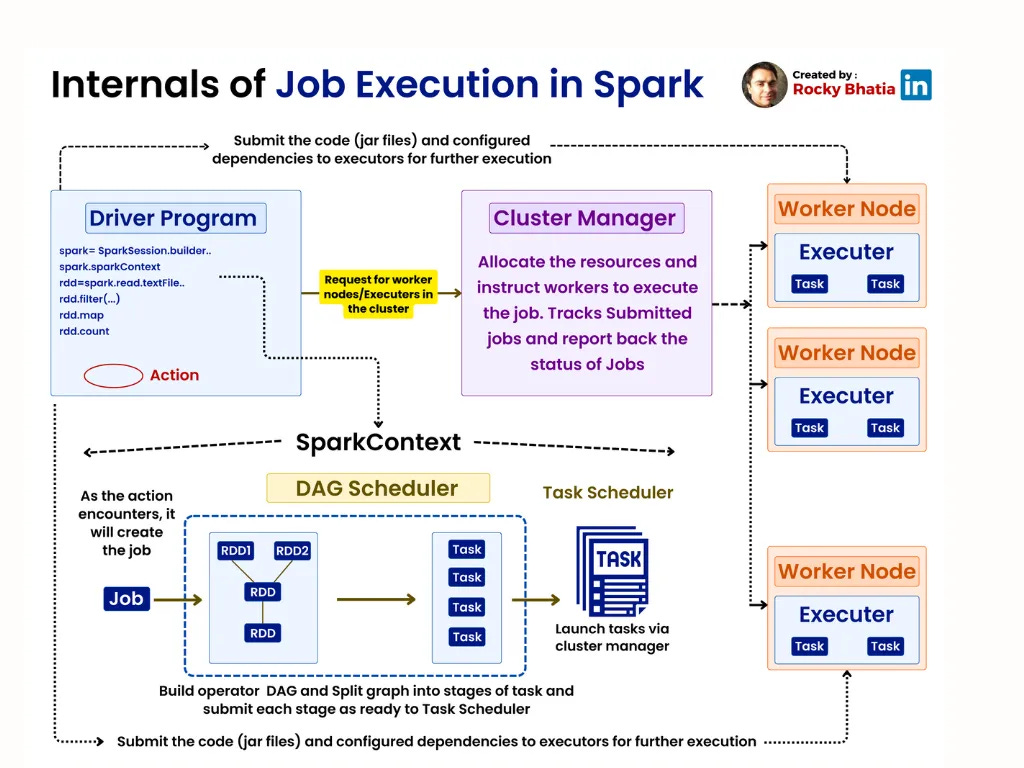
Because machine learning workloads are so compute-intensive, Databricks’ initial customer base was data scientists and machine learning engineers, typically at large companies. Contrast this to Snowflake, whose workloads were much more focused on business intelligence.
It’s important to call out that Spark is a processing framework, not a database. So, it’s a way to distribute compute workloads rather than store data. It sits on top of raw object storage like S3, typically running workloads on structured and semi-structured data. This is a fundamentally different value proposition than a tool like Snowflake, which started out as a data warehouse designed for structured data.
Sparks fly…eventually so does Databricks
From 2013-2015, the team continued to build out the Spark project, looking for the proverbial “product market fit.”
In 2015, in Ghodsi’s words, “Spark exploded…at that point we felt like we had succeeded, but we just didn't have any monetization. So we went through a difficult time in 15 and we had to figure out, okay, if we can't monetize, maybe there is nothing here. Uh, and the company kind of went through a little bit of introspection.”
Ali Ghodsi then steps in as CEO in 2016, and the leadership team changed, as Databricks brought in a team that had experience selling enterprise software.

Most of the original founding team stayed at the company (and is still involved today), but they led technology while the new team focused on commercializing that technology.
Part of this change required making Databricks a little bit less open-source. Ghodsi said, “So we need proprietary secret sauce, sauce that we're not just giving away to the hyperscalers. So that was critical also in changing, and that's difficult to do…but it was the only way to succeed. We wouldn't have been around if we hadn't done that pivot.”
Tailwind #3: The Rise of Open Source
The monetization of open-source tech remains a problem for startups today, and one without a one-size-fits-all solution. But Databricks decides to start keeping more of Spark’s features proprietary so they have a value proposition to sell to customers.
How does Databricks make money? Since Databricks doesn’t store data, they made their revenue from charging a hefty margin on their compute costs. That was built on the cloud infrastructure providers, so Databricks takes an additional margin on their costs. Because of the nature of big data, Databricks sold to very large enterprises or startups with large amounts of data.
From this point on, the business really takes off:
In 2017, Databricks makes a really smart strategic move with a partnership with Microsoft Azure. This was a jointly developed product where Microsoft customers could purchase Azure Databricks, integrate with other Azure services, and both Databricks and Microsoft recognize revenue. They leverage the distribution network and sales teams of Microsoft while establishing their own technology within Microsoft’s customer base.
Perhaps lessons from this helped inform Microsoft’s OpenAI partnership.
Databricks goes Mainstream
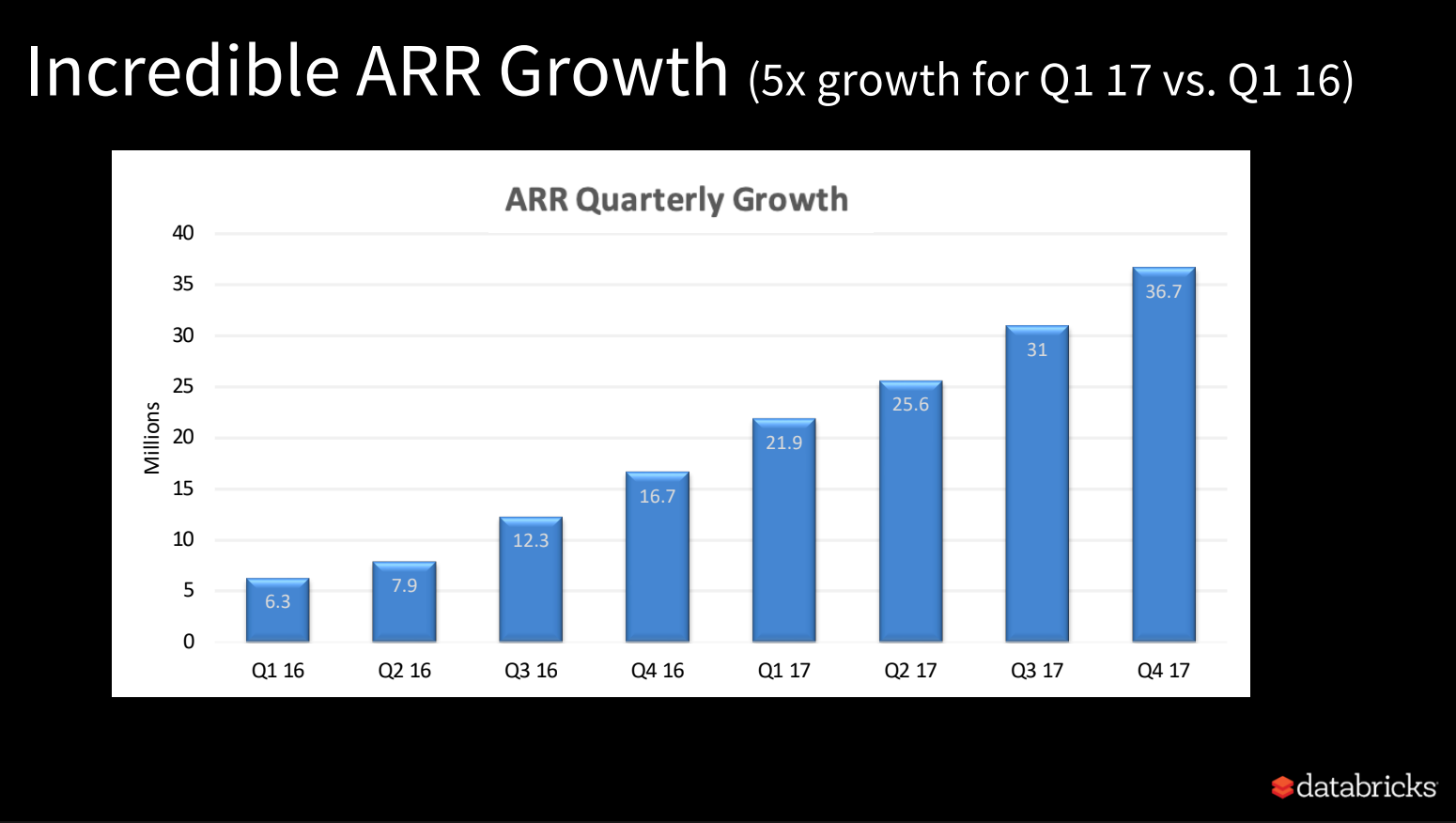
Over the next five years, Databricks would raise five rounds of venture funding and take them from a $520M valuation to a $28B valuation:
Series D of $140M in 2018
Series E of $250M in 2019
Series F of $400M in 2019
Series G of $1B in 2021
Series H of $1.6B in 2021, valuing them at $28B
Over that time, they’d pursue a key piece of their strategy: becoming a platform. They’d release two more pillars of the open-source data/AI community: Delta Lake and MLflow.
MLflow provided an open-source framework to build out ML models. Delta Lake provided an “open table” format which provided a way to store metadata about data in data lakes, which allowed more efficient organization and processing of that data.

Perhaps, most importantly, this laid the groundwork for Databricks “data lakehouse” vision, which brings us full circle to Databricks “Big Picture” in 2013: a unified platform for analytics.
Over the 2010s, data management had diverged in two paths: data warehouses for SQL-based analytics and data lakes for storing bulk, unstructured data. Both had problems:
Data warehouses were expensive, closed-source, and didn’t handle unstructured data well.
Data lakes were difficult to manage, leading to data disorganization.
Databricks went full steam ahead on the data lakehouse vision to finally bring their vision to life. The lakehouse merged the data lake and the data warehouse, bringing three primary benefits: centralizing data management onto one platform, opening the data platforms to open-source tools, and doing so at a theoretically cheaper price. (I wrote a full article the lakehouse last year.)
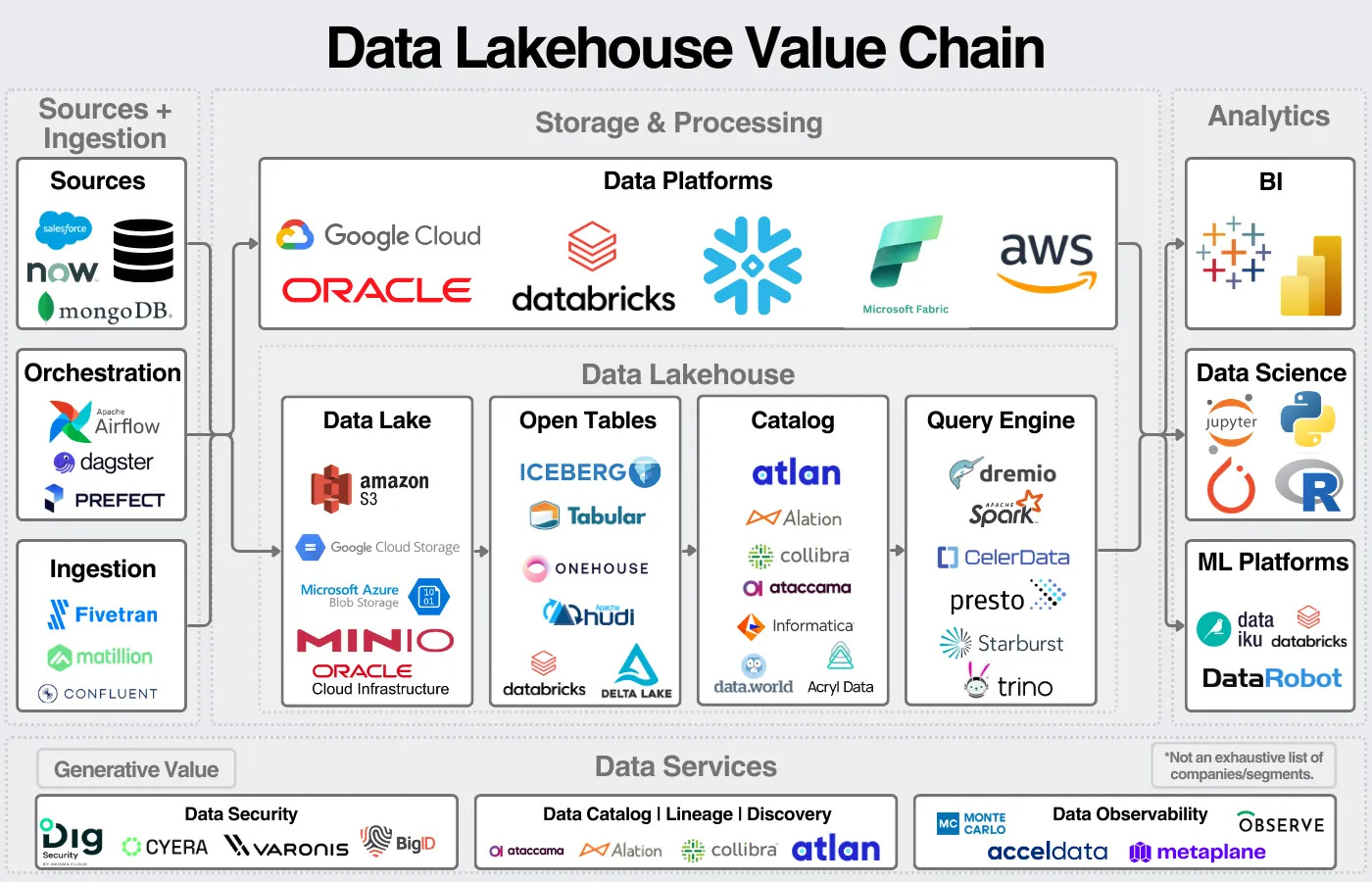
Databricks did a wonderful job marketing the lakehouse, bringing us back to the key point: one platform for all your data, and easily get insights from that data.
It also opened the door for Databricks to release Databricks SQL, a competitive data warehouse to Snowflake that now makes up 20% of their revenue. If you’re going to store all your data on one platform, you need to store both your structured and unstructured data!
The Current State of Databricks
Databricks had spent a decade building its reputation in the AI/ML community. By the time the ChatGPT moment hit, they were wonderfully positioned.
They’ve made acquisitions and product releases over the last two years to enable the entire data and AI workflow. This includes ingestion, orchestration, transformation, processing, SQL database, and a host of AI tools (agent frameworks, agent evaluation, vector search, AI governance, model fine-tuning services, and managed MLflow).
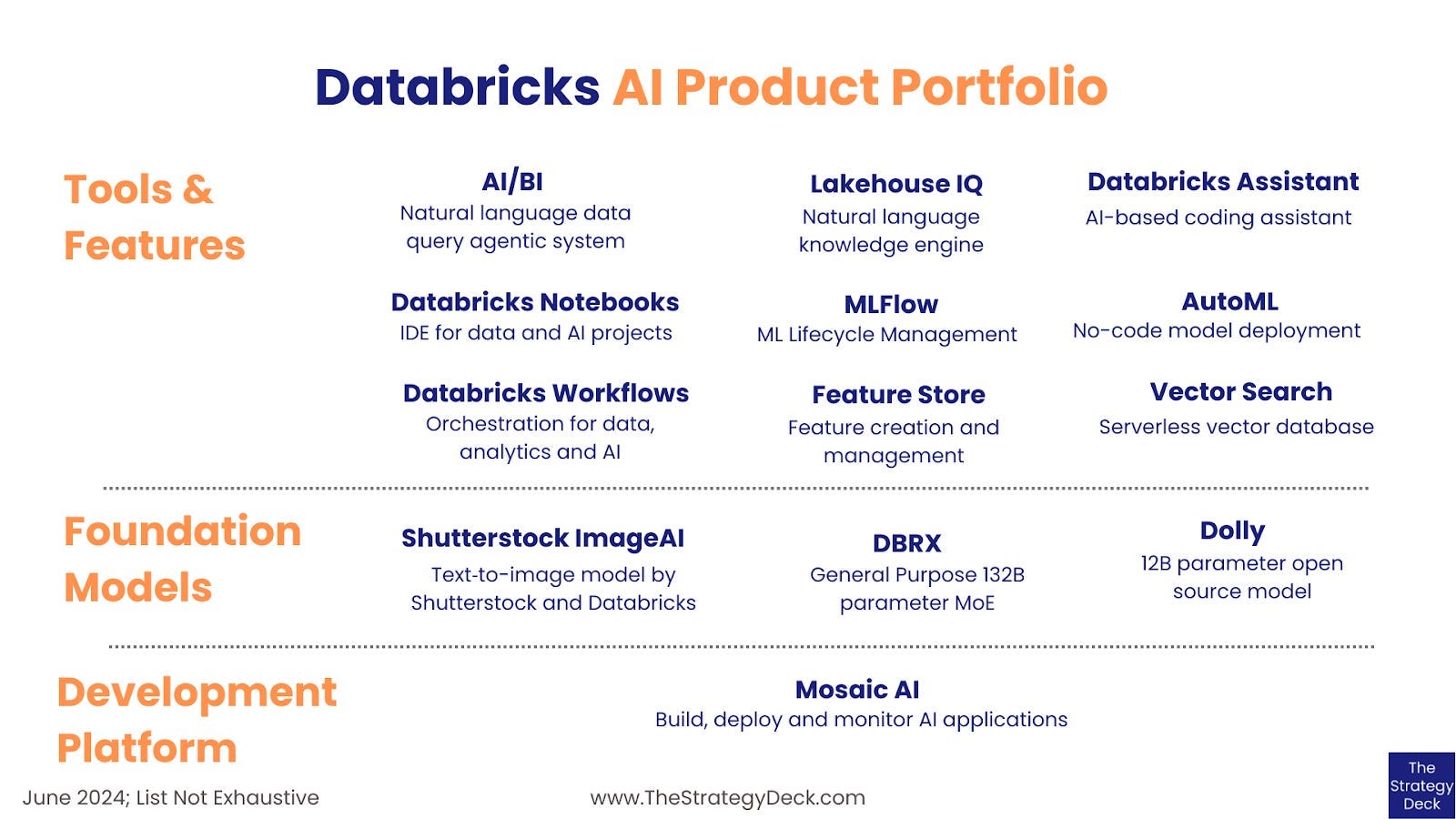
I want to take a step back because the challenge with understanding platforms is the thousands of features they offer. Databricks can be broken down simply: they aim to be the unifying layer for data and enable companies to get insights from that data.
Data science: Data science jobs, running on managed Spark in the backend, writing code in Databricks notebooks.
Data warehousing: Store all your structured data and query it.
Data engineering: Pipelines, orchestration, transformation.
Build your own AI: Traditional ML (MLflow, feature stores, model serving, training models, fine-tuning models) and Agents (Agent frameworks, vector stores)
Governance & security: Index all of your data assets (know where they are, what’s in it, and who should have access to it)
AI on top of that: I speculate Databricks envisions a world where you have one application for your data, one agent if you will. You ask that data agent any question you want and it can answer it for you. That’s been the vision from the beginning: don’t ask what happened last week, ask what’s going to happen next week.
The Business Today
This brings us to the current state of the business today. In December of 2024, Databricks raised a $10B round valuing the company at $62B. With that announcement, we got a look at their financials as well:
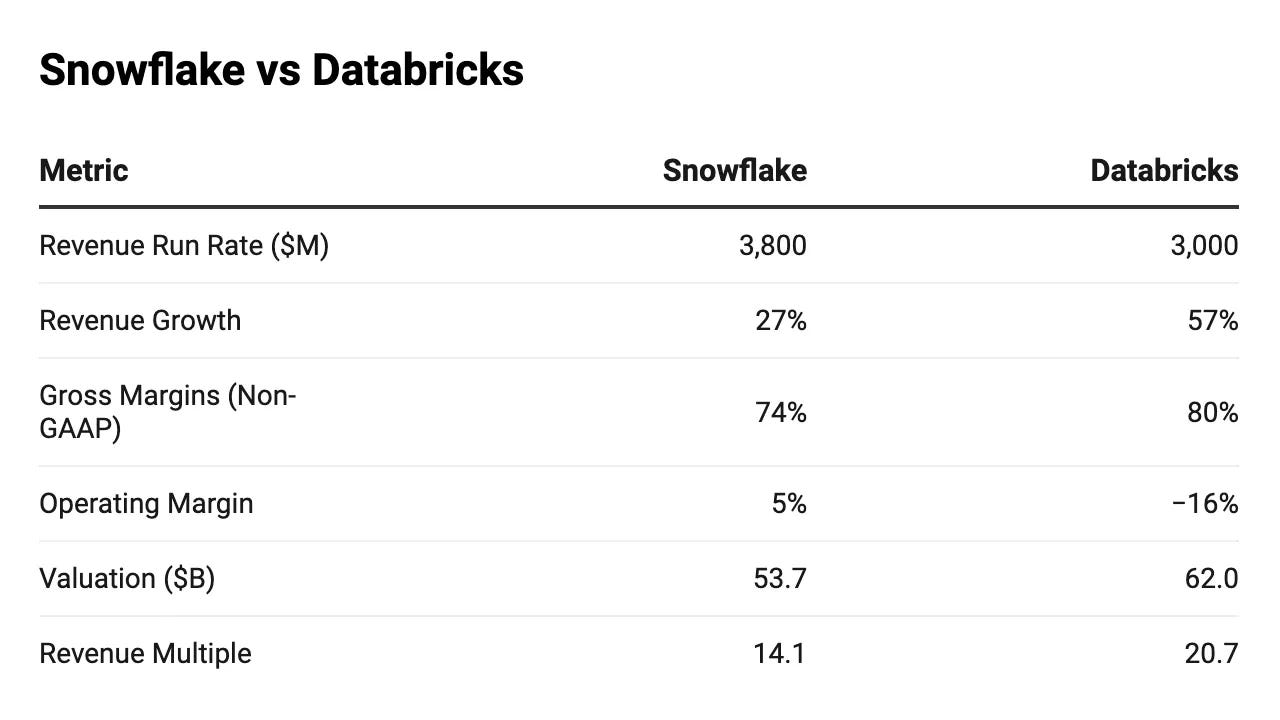
To be clear, the moats in enterprise data are exceptional. Databricks will be around a decade from now and they’ll be important a decade from now.
From an investment perspective, the uncertainty comes from valuations and growth expectations. Databricks had a $3B annual revenue run rate, up 60% from ~$1.9B run rate at the end of 2023. That values them at a Price/Run Rate of ~21, and a price/run rate/growth of ~.35. If we compare that to comps of other data companies, that seems like a reasonable price to pay:

What’s particularly interesting is that while the rest of the industry’s growth slows, Databricks’ growth is accelerating. They accelerated growth by 10% Y/Y, while the other three companies shown declined ~7% Y/Y on average. There may be something to this whole AI business after all!

At a macro level, the questions around Databrick's valuation come down to industry growth as a whole, how long Databricks can sustain its outperformance, and wide-scale multiple contraction or expansion in data companies.
Now, I alluded to the big question of this article at the beginning: how do you effectively ride S curves?
Databricks & The Path Ahead
At an industry-wide level, we’re simultaneously seeing the consolidation of software and the rise of AI. I suspect how Databricks navigates these trends will determine their next decade.
As I see it, this leads to three key elements of their strategy:
1. Offering a Platform in Times of Consolidation
After a decade of rapid growth, enterprise SaaS is consolidating. As Redpoint put it, “Market Leaders Have Continued to Benefit Disproportionately.”

What that means is that you want to be as broad of a platform as possible for your specific customer base. And that’s exactly what Databricks has done: releasing more and more features to support the entire data ecosystem.
Now, this is powerful alone, but it’s even more powerful with open-source. The power isn’t just being a platform, it’s in being an open-source distribution network.
2. Becoming the Open-Source Data Distribution Network
From the beginning, Databricks has been an open-source-first company. Initially, this was the value prop: open-source is wonderful but it’s hard to manage. Let us handle the hard stuff.
Now that open-source has exploded, the value prop is this: let us handle all of your open-source, we’ll offer a managed version and you just build great products.
This is so brilliant because the better open-source does, the better Databricks does. This creates an open-source flywheel: The more open-source products you use on Databricks, the harder it is to switch.

This was the same dynamic that Databricks had to fight off from the hyperscalers in the early years!
Finally, these first two strategies are positioning for industry consolidation. The last point is positioning for industry growth.
3. Becoming the AI Database
Ghodsi described the future of Databricks, ”Basically Databricks [is] an AI database. We don't call it that. We don't market it that way, but essentially it's an AI database under the hood. And you will need that for every application, every company in the planet will need that. And, you know, I hope that we can be the company that powers all of these applications in the future.”
To succeed in this, Databricks needs to do two things: convince startups to build on their platform and build as many native integrations as possible with AI applications.
The first allows Databricks to profit from the coming wave of AI applications, and the second protects Databricks core data business.
Like I said prior, Databricks will be around a decade from now and they’ll be important a decade from now.
The question comes down to how much bigger they’ll be. The answer to that comes down to execution.
Two years ago, I speculated Databricks wanted to be the biggest tech IPO ever. That sight is still within reach. Meta IPO’d at a market cap of $81B in 2012 according to Pitchbook. Could Databricks IPO at a $100B market cap in the coming years?
There are a lot of questions between now and then, but I don’t see why not.
As always, thanks for reading!
Disclaimer: The information contained in this article is not investment advice and should not be used as such. Investors should do their own due diligence before investing in any securities discussed in this article. While I strive for accuracy, I can’t guarantee the accuracy or reliability of this information. This article is based on my opinions and should be considered as such, not a point of fact. Views expressed in posts and other content linked on this website or posted to social media and other platforms are my own and are not the views of Felicis Ventures Management Company, LLC.