
OpenAI, Part 2
Technology, Business Model, Financials, and Competitive Landscape for the AI Giant

As I said in my first OpenAI article, “If there’s one company to study to understand AI, it’s OpenAI.”
Well, that’s not as easy as it sounds. OpenAI might be as complex as they are important.
The goal of this article is very simple: to explain OpenAI. Its technology. Its business model. Its current state today.
This article has three sections:
A Primer on OpenAI’s Technology (Deep Learning, LLMs, Reasoning, Agents)
A Breakdown of OpenAI’s Business (Business Model, Revenue, Competition)
Market Statistics & Competitive Landscape
If my first OpenAI article was its history, this is its present, and the final article will be its future (or at least the questions I’m thinking about for its future).
For a reminder on OpenAI’s history, here’s how we got here:

1. OpenAI’s Technology
To start, I have a confession to make: I originally wrote several thousand words on OpenAI’s technology. But I felt it didn’t really provide an understanding of their technology. My conclusion was this: it’s really hard to explain LLMs without telling the story of how we got here.
For deep dives into LLMs, there are three sources I recommend:
Stephen Wolfram’s “What Is ChatGPT Doing … and Why Does It Work?”
Bonus: Many hours at dinners with Devansh asking, “Wait, can you explain that again?” over and over again.
The hyper-condensed evolution of AI has been: the conceptualization of AI → decades of research → the deep learning breakthrough → attention & transformers → early LLMs → ChatGPT → reasoning → agents and beyond.
Each of these steps provided a building block for LLMs, and I’ll do my best to distill the key ideas below (and I’m well aware it takes a niche, curious fellow to enjoy my articles. I don’t blame you if you bow out now!)
The Roots of AI
The core idea of AI is the automation of routine human tasks and the pursuit of human resemblance.
Calculators were a form of artificial intelligence, then mainframes, then software, and now LLMs. The evolution of computing has led us closer and closer to Alan Turing’s original description for AI:
“What we want is a machine that can learn from experience…[the] possibility of letting the machine alter its own instructions provides the mechanism for this.”
In the 1940s, neural networks, the foundation of AI systems today, were theorized. Neural nets are models made up of layers of “nodes”, like dials that can be tuned. By “weighing” the relationships between many nodes, neural networks can model complex systems. Generally, the more “nodes”, the more complex systems they can model.

These models are trained on data from the complex systems they’ll represent. The goal is to “minimize loss” between actual data and predicted data. Typically, the more data provided, the better the model.
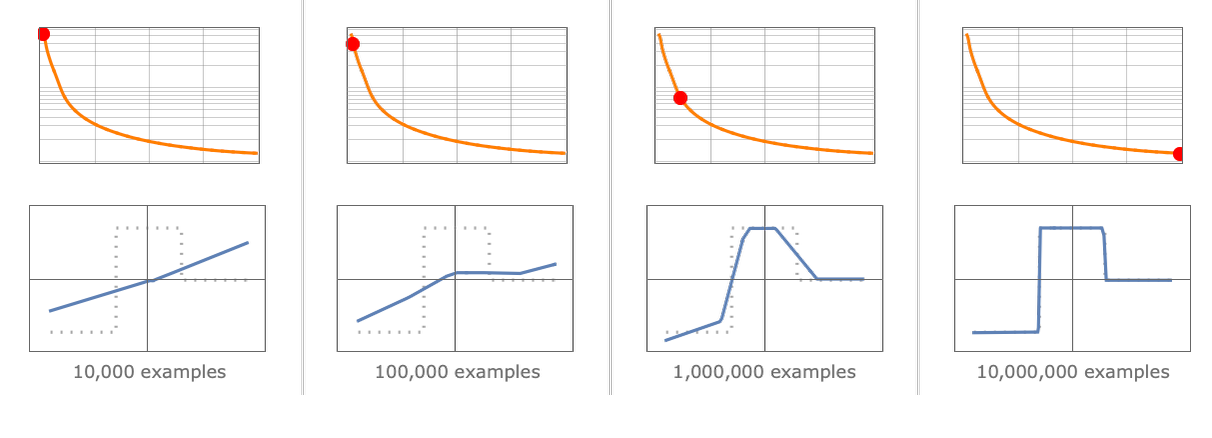
It took many decades to see the practical development of neural networks. Two unlocks brought about modern deep learning: the rise of big data and the parallel computing ability of Nvidia GPUs.
The AlexNet breakthrough happened in 2012, which marked a huge jump in performance in artificial neural networks. One key breakthrough: parallelize workloads with GPUs.
Modern AI Systems - The Black Box of LLMs
The next building block for AI was transformers, released in Google’s 2017, now famous “Attention is All You Need” paper.
The key idea here is that, via “attention”, you can incorporate context into the meaning of a word. For example, “float” can mean to float on water, a root beer float, a parade float, or even floating on cloud nine. Transformers provide a mechanism to incorporate that meaning into a word.
LLMs first take a given dataset (your prompt), break it into tokens (small bits of data like word fragments), map out the meanings of those words (embeddings) into vectors (columns of data):

At this point, the model has a set of vector embeddings representing the given dataset (the input).
Then, the “transformer” comes into play. Its goal is to create a new series of vectors that incorporate the surrounding meaning of words. The key idea with the transformer is attention: process all the words at once, don’t translate one-by-one. Essentially, they look at the relations between words in an attention grid:

That then goes through a feed-forward layer, which refines the information extracted by attention.
This process is continually repeated as the data passes through the model, updating the embeddings to better predict the “right answer.”
After the data has been processed, it outputs a list of probabilities of potential words (just like there are many words we can choose to use with the same meaning). That final embedding is “unembedded” into words and outputted.
OpenAI’s Technology Today: Scale, Reasoning, and Agents
LLMs then took the transformer architecture and trained on language. Which resulted in early models that weren’t very good. So what’d they need to get to the quality of today's LLMs? Scale.
More data, more GPUs, (and now more data centers and energy) = better performance, until the models very effectively modeled language!
There are undoubtedly many innovations I’m skipping over that make ChatGPT such an incredible product. Those innovations combined with continued scale led to increasing model improvements.
For modern AI systems, OpenAI has laid out five levels of AI:

Reasoning recently took center stage. Essentially, reasoning models generate several possible outputs, evaluate which is best, and then move forward with that selection. This operates much more similarly to human thought processes.

As OpenAI describes, “Through reinforcement learning, o1 learns to hone its chain of thought and refine the strategies it uses. It learns to recognize and correct its mistakes. It learns to break down tricky steps into simpler ones. It learns to try a different approach when the current one isn’t working. This process dramatically improves the model’s ability to reason.”
Finally, agents give LLMs the ability to take actions. Turning them from a better search experience to a legitimate human labor alternative (for very simple tasks, today at least).
A new and improved version of search is good, but not life-changing. If you have agents who can complete tasks, schedule vacations, book hotels, respond to emails, handle customer service requests, can schedule calendar invites, that’s life-changing!
Are we there today? No.
Are we there next year? Maybe.
Are we there a decade from now? Definitely.
This is the path forward for OpenAI, and as they described themselves,“We are now confident we know how to build AGI as we have traditionally understood it. We believe that, in 2025, we may see the first AI agents “join the workforce” and materially change the output of companies.
This brings us to the current state of OpenAI’s technology.

2. OpenAI’s Business
*nervous investor laughs - finally back to the safe confines of finance*
I can confidently summarize OpenAI’s business model in a few brief sentences: They’re the vertically integrated AI company. Models are their differentiator. They’re vertically integrating up the stack to create application revenue and moats. They’re vertically integrating down the stack for marginal cost improvements.
The Financials
Models get discussed a lot, as they should, but ~72% of OpenAI’s revenue comes from ChatGPT:

OpenAI was reportedly expected to generate ~$4B in revenue in 2024, with a $5B loss.
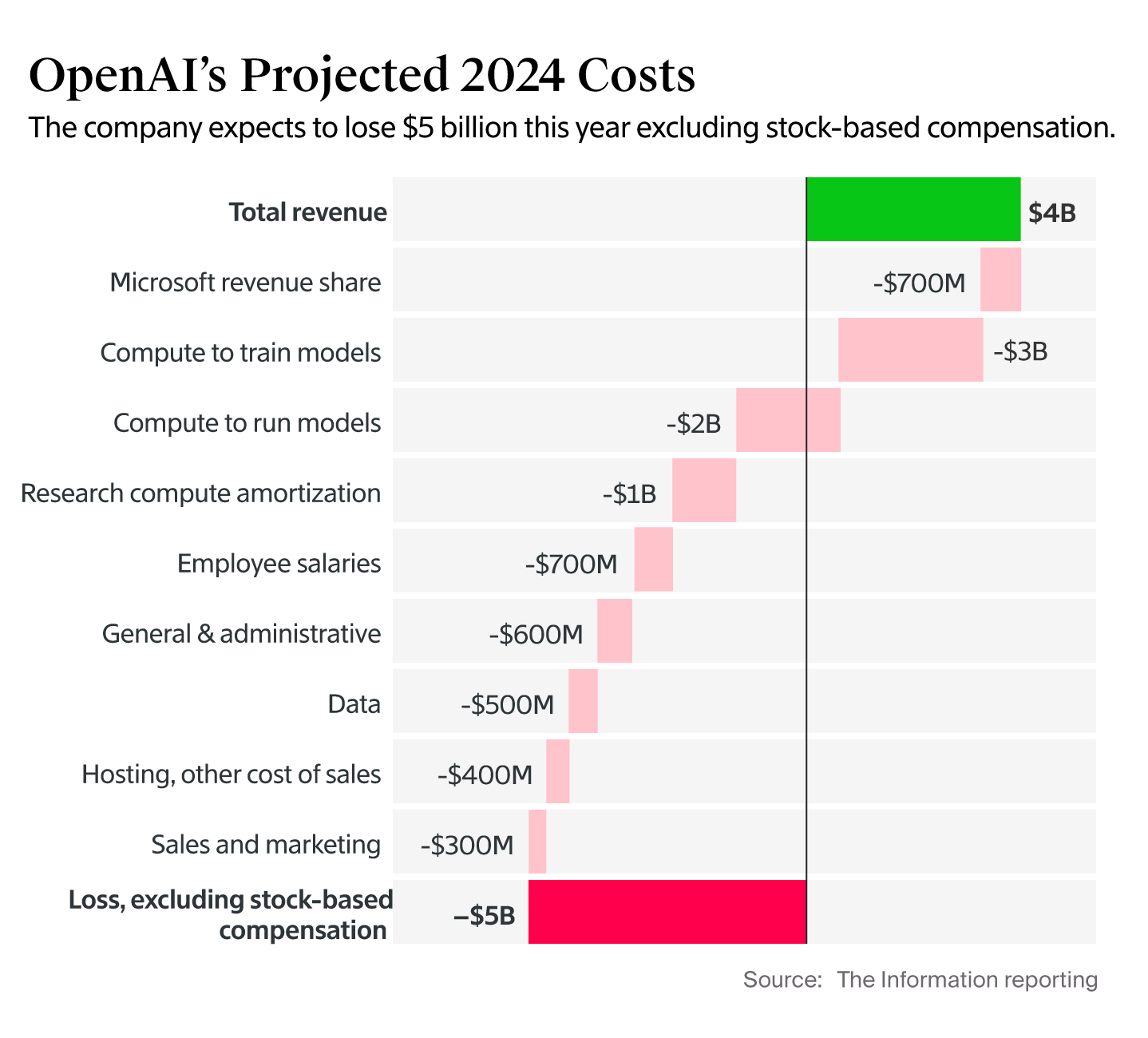
On that $4B in revenue, their gross margin was approximately 41%. I speculate that number only includes hosting and inference costs (but someone correct me if they know otherwise).
They do expect that margin to improve to 67% in 2028 (not your grandpa’s software margins eh!) They expect to hit profitability in 2029 when their revenue surpasses $100B.
How do they expect to get to $100B in revenue?
The answer to that comes from a very interesting chart:

Now, this chart is particularly redeeming for OpenAI in the context of the DeepSeek announcement. Their path to $100B in revenue doesn’t run through the API, it runs through applications.
Even in 2025, it expects “new products” to surpass API revenue.
A moment of speculation: we should not view ChatGPT as a chatbot but as a general-purpose agent. From what I can see, the vision for ChatGPT is to become everyone’s executive assistant. It integrates with all of your accounts, stores your preferences, listens to meetings, takes notes, schedules follow-ups, and responds to simple emails. This is the ChatGPT that gets to $50B in revenue, not a chatbot.
Corporate Governance Structure
When I said earlier, “OpenAI might be as complex as they are important,” I had this section in mind. Their corporate structure is below:

If that’s not complex enough, they have their Microsoft relationship as well:

Reportedly, Microsoft gets 20% of OpenAI’s revenue (and profits up to $92B). Microsoft gives 20% of revenue from Azure OpenAI API to OpenAI. In addition, Microsoft owns a large stake in OpenAI (it’s unclear how much that is and will likely change when OpenAI changes its structure; some news outlets reported up to 49% ownership).
Pending its outcome, Microsoft’s OpenAI investment looks like an all-time great one.
One particular friction point was Microsoft’s exclusivity as OpenAI’s cloud provider, but that seems to have changed with the Stargate announcement.
3. Market Statistics & The Competitive Landscape
I want to end with data I’m seeing in the market on competitors, fundraising, and market share.
Now, a very important disclaimer to be skeptical of any benchmarks you see. As a friend recently tweeted,”I never met a benchmark I didn’t like.” Because of this, I won’t attempt to answer the “Who has the best model?” question. Additionally, I only lightly touch on the open-source and big tech competitors not directly profiting from LLMs.
Anthropic, OpenAI’s most direct competitor, was estimated to have hit a $960M annual run rate by the end of 2024, and is expected to generate between $2B-$4B in revenue in 2025. Compared to OpenAI’s projections of $12B.
What’s particularly interesting is the divergence we’re seeing between model market share and application market share for OpenAI. On models, we’re seeing the market become increasingly competitive:

On benchmarks, we’re seeing a similar trend. OpenAI has the highest quality models, but the leader for performance/price ratio is debated.

DeepSeek R1, for example, is competitive with both o3-mini and o1-mini, on a price/performance ratio.

Now, part of this competition can be attributed to the fact that o3 is not fully released, OpenAI continues to focus more efforts on releasing agents, and they reportedly have healthy margins on their API.
Regardless, it’s still a clear departure from its application business, where ChatGPT is becoming increasingly dominant:

I’ll be writing more about what I think this means for the landscape over the coming weeks; in summary: I think it’s a broader trend of model competition that will force foundation model companies to differentiate and profit in other ways.
The data shows that for OpenAI, even if they maintain model leadership, the path toward a sustainable business model is through applications.
4. Some Final Thoughts
I’ll end with a quick thought (for anyone left still reading!) We live in an information-soaked world where little value is left in data collection.
For better or worse, this article was intentionally about data collection. It was about setting out, as clearly as possible, the state of OpenAI. And that state is as follows:
Deep learning was unlocked by GPUs and the rise of big data.
Transformers unlocked context, a key component of language.
OpenAI brought that to the masses with ChatGPT.
OpenAI became one of, if not the fastest-growing company in history.
They released agents, reasoning, voice, and search to develop ChatGPT as a general-purpose assistant.
Competition moved into the model layer but hasn’t broken ChatGPT’s first-mover advantage at the application layer.
They’re vertically integrating up and down the stack to become the vertically integrated AI company.
My final article in this series will be the questions that I think are most important to OpenAI’s future.
After all, “we think far less than we think,” and value’s only left to be generated by those willing to do so.
As always, thanks for reading!
Disclaimer: The information contained in this article is not investment advice and should not be used as such. Investors should do their own due diligence before investing in any securities discussed in this article. While I strive for accuracy, I can’t guarantee the accuracy or reliability of this information. This article is based on my opinions and should be considered as such, not a point of fact. Views expressed in posts and other content linked on this website or posted to social media and other platforms are my own and are not the views of Felicis Ventures Management Company, LLC.
Great read... looking forward to your final part.
Hey Eric, good job, summarizing (sort of and without all the drama) their journey so far, and you avoided getting to technical 👍Looking forward to read your final part!