
The AI Semiconductor Landscape
An overview of the technology, market, and trends in AI semiconductors


Nvidia’s rise in the last 2 years will go down as one of the great case studies in technology.
Jensen envisioned accelerated computing back in 2006. As he described at a commencement speech in 2023, ”In 2007, we announced [released] CUDA GPU accelerated computing. Our aspiration was for CUDA to become a programming model that boosts applications from scientific computing and physics simulations, to image processing. Creating a new computing model is incredibly hard and rarely done in history. The CPU computing model has been the standard for 60 years, since the IBM System 360.”
For the next 15 years, Nvidia executed on that vision.
With CUDA, they created an ecosystem of developers using GPUs for machine learning. With Mellanox, they became a (the?) leader in data center networking. They then integrated all of their hardware into servers to offer vertically integrated compute-in-a-box.
When the AI craze started, Nvidia was the best-positioned company in the world to take advantage of it: a monopoly on the picks and shovels of the AI gold rush.
That led to the rise of Nvidia as one of the most successful companies ever to exist.
With that rise came competition, including from its biggest customers. Tens of billions of dollars have flowed into the ecosystem to take a share of Nvidia’s dominance.
This article will be an overview of that ecosystem today and what it may look like moving forward. A glimpse at how we map out the ecosystem before we dive deeper:

I teamed up with Austin Lyons from Chipstrat to write this article. I highly recommend giving him a follow. He provides some of the best semiconductor analysis online and has done particularly excellent work in edge AI. For both business strategy and technical details, it’s a must-read publication (and to be clear, this is a non-sponsored recommendation).
1. Some Background on AI Accelerators
At a ~very~ high level, all logic semiconductors have the following pieces:
Computing Cores - run the actual computing calculations.
Memory - stores data to be passed on to the computing cores.
Cache - temporarily stores data that can quickly be retrieved.
Control Unit - controls and manages the sequence of operations of other components.
Traditionally, CPUs are general-purpose computers. They’re designed to run any calculation, including complex multi-step processes. As shown below, they have more cache, more control units, and much smaller cores (Arithmetic Logic Units or ALUs in CPUs).
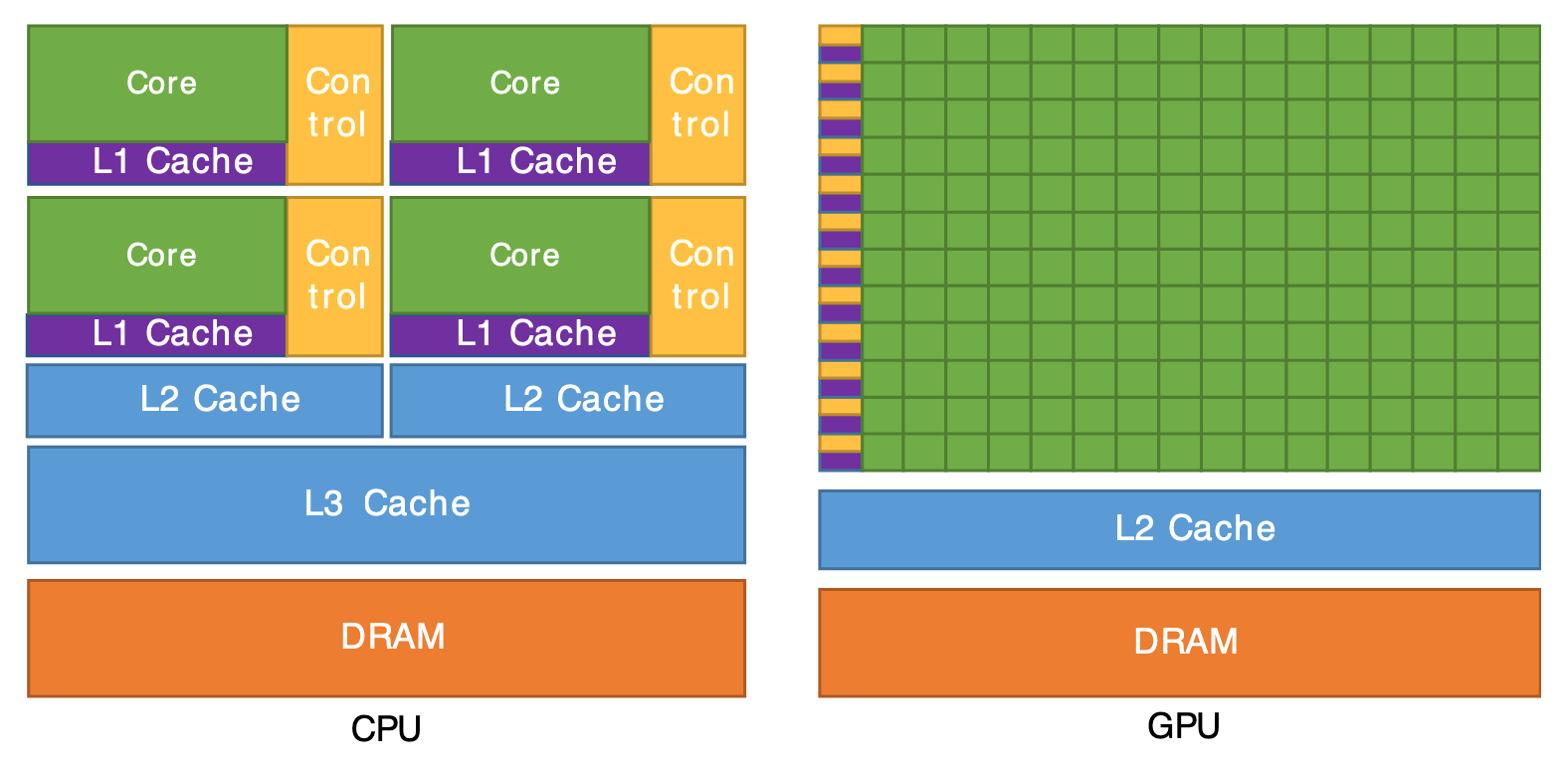
On the other hand, GPUs are designed for many small calculations or parallel processing. Initially, GPUs were designed for graphics processing, which needed many small calculations to be run simultaneously to load displays. This fundamental architecture translated well to AI workloads. Nvidia pioneered programmable shaders with their early GPUs and would release CUDA to turn all GPUs into programmable computers.
Why are GPUs so good for AI?
The base unit of most AI models is the neural network, a series of layers with nodes in each layer. These neural networks represent scenarios by weighing each node to most accurately represent the data it's being trained on.
Once the model is trained, new data can be given to the model, and it can predict what the outputted data should be (inference).
This “passing through of data” requires many, many small calculations in the form of matrix multiplications [(one layer, its nodes, and weights) times (another layer, its nodes, and weights)].
This matrix multiplication is a perfect application for GPUs and their parallel processing capabilities.

(Stephen Wolfram has a wonderful article about how ChatGPT works.)
The GPU today
GPUs continue to get larger, with more computing power and memory, and they are more specialized for matrix multiplication workloads.
Let’s look at Nvidia’s H100 for example. It consists of CUDA and Tensor cores (basic processors), processing clusters (collections of cores), and high-bandwidth memory. The H100’s goal is to process as many calculations as possible, with as much data flow as possible.

The goal is not just chip performance but system performance. Outside of the chip, GPUs are connected to form computing clusters, servers are designed as integrated computers, and even the data center is designed at the systems level.
2. Background on Training vs Inference
To understand the AI semiconductor landscape, we have to take a step back to look at AI architectures.
Training iterates through large datasets to create a model that represents a complex scenario, and inference provides new data to that model to make a prediction.

A few key differences are particularly important with inference:
Latency & Location Matter - Since inference runs workloads for end users, speed of response matters, meaning inference at the edge or inference in edge cloud environments can make more sense than training. In contrast, training can happen anywhere.
Reliability Matters (A Little) Less—Training a leading-edge model can take months and requires massive training clusters. The interdependence of training clusters means mistakes in one part of the cluster can slow down the entire training process. With inference, the workloads are much smaller and less interdependent; if a mistake occurs, only one request is affected and can be rerun quickly.
Hardware Scalability Matters Less - One of the key advantages for Nvidia is its ability to scale larger systems via its software and networking advantages. With inference, this scalability matters less.
Combined, these reasons help explain why so many new semiconductor companies are focused on inference. It’s a lower barrier to entry.
Nvidia's networking and software allow it to scale to much larger, more performant, and more reliable training clusters. For the most part, that’s an impenetrable moat today.
On to the competitive landscape.
3. The AI Semiconductor Landscape
We can broadly look at the AI semiconductor landscape in three main buckets:
Data Center Chips for Training
Data Center Chips for Inference
Edge Chips for Inference
Visualizing some of those companies below:
The Data Center Semiconductor Market
Put simply, Nvidia dominates data center semiconductors, with AMD as the only legitimate general-purpose alternative. The hyperscalers develop in-house chips, and most startups focus on inference or specialized hardware for specific architectures.
Nvidia will sell $100B+ in AI systems in 2024. AMD is in clear second place, expecting $5B in revenue in 2024.
Across all data center processors, we can see market share at the end of 2023 here:

Google offers the most advanced accelerators of the hyperscalers, with their TPUs. TechInsights estimated they shipped 2 million TPUs last year, putting it behind only Nvidia for AI accelerators.
Amazon develops in-house networking chips (Nitro), CPUs (Graviton), inference chips (Inferentia), and training chips (Trainium). TechInsights estimated they “rented out” 2.3M of these chips to customers in 2023.
Microsoft recently announced both a CPU (Cobalt) and a GPU (Maia). They’re too new to tell any real traction yet.
Finally, I’ll point out that Intel was initially expected to sell ~$500M worth of its Gaudi 3 this year, but reported last earnings call that they will not achieve that target.
With its software and networking, Nvidia dominates training. But! Inference provides a more competitive landscape due to the aforementioned architectural differences.
Inference provides a more interesting conversation!
RunPod published an interesting comparison between the Nvidia H100 and the AMD MI300X, and found that the MI300X provides more cost-advantageous inference in very large batch sizes and very small batch sizes.

We also have several hardware startups that have raised significant funding to capture a piece of this market:

An interesting trend emerging in this batch of startups is the expansion up stack to software. Three of the most notable startups in the space (Groq, Cerebras, and SambaNova) are all offering inference software. This vertical integration, in theory, should provide cost and performance benefits to end users.
The final piece of the AI semiconductor market that everyone is thinking about is AI at the edge.
4. AI on the Edge?
Training the largest and most capable AI models is expensive and can require access to entire data centers full of GPUs. Once the model is trained, it can be run on less powerful hardware. In fact, AI models can even run on “edge” devices like smartphones and laptops. Edge devices are commonly powered by an SoC (System on a Chip) that includes a CPU, GPU, memory, and often an NPU (Neural Processing Unit).

Consider an AI model on a smartphone. It must be compact enough to fit within the phone's memory, resulting in a smaller, less sophisticated model than large cloud models. However, running locally enables secure access to user-specific data (e.g., location, texts) without transferring it off the device.
The AI model could technically run on the phone’s CPU, but matrix multiplication is better suited to parallel processors like GPUs. Since CPUs are optimized for sequential processing, this can lead to slower inference, even for small models. Running inference on the phone’s GPU is an alternative.
However, smartphone GPUs are primarily designed for graphics. When gaming, users expect full GPU performance for smooth visuals; simultaneously allocating GPU resources to AI models would likely degrade the gaming experience.
NPUs are processors tailored for AI inference on edge devices. A smartphone can use the NPU to run AI workloads without straining the GPU or CPU. Given that battery life is crucial for edge devices, NPUs are optimized for low power consumption. AI tasks on the NPU may draw 5–10x less power than the GPU, making them far more battery-friendly.
Edge inference is applied in sectors like industrial and automotive, not just consumer devices. Autonomous vehicles rely on edge inference to process sensor data onboard, allowing the quick decisions needed to maintain safety. In industrial IoT, local AI inference of sensor and camera data enables proactive measures like predictive maintenance.
With more available power than consumer devices, industrial and automotive applications can deploy high-performance computing platforms, like Nvidia’s Orin platform, featuring a GPU similar to those in data centers. Use cases that benefit from remote hardware reprogrammability can leverage FPGAs, for example from Altera.
5. Some Thoughts on the Market
To end with some musings on the market, I’ll touch on three questions I find most interesting in the space:
1. How deep is Nvidia’s moat?
Nvidia has sustained a 90%+ market share in data center GPUs for years now. They’re a visionary company that has made the right technical and strategic moves over the last two decades. The most common question I get asked in this market is about Nvidia’s moat.
To that, I have two conflicting points: First, I think Nvidia is making all the right moves, expanding up the stack into AI software, infrastructure, models, and cloud services. They’re investing in networking and vertical integration. It’s incredible to see them continue to execute.
Secondly, everyone wants a piece of Nvidia’s revenue. Companies are spending hundreds of billions of dollars in the race to build AGI. Nvidia’s biggest customers are investing billions to lessen their reliance on Nvidia, and investors are pouring billions into competitors in the hopes of taking share from Nvidia.
Summarized: Nvidia is the best-positioned AI company on the planet right now, and there are tens of billions of dollars from competitors, customers, and investors trying to challenge them. What a time to be alive.
2. What’s the opportunity for startups?
Semiconductor startups face a brutal uphill climb to a sustainable business model. When you’re competing against Nvidia, that feels extra true. That said, there’s always a trade-off between generality and specificity. Companies that can effectively specialize in large enough markets can create very large businesses. This includes both inference-specific hardware and model-specific hardware.
I’m particularly interested in approaches that can enable faster development of specialized chips. This helps lower the barrier to entry of chip development while taking advantage of the performance benefits of specialization.
But semiconductors are hard, and it will take time and several generations for these products to mature. These companies will need continued funding to pursue those several generations.
3. Will we get AI at the edge?
If we look at the history of disruption, it occurs when a new product offers less functionality at a much lower price that an incumbent can’t compete with. Mainframes gave way to minicomputers, minicomputers gave way to PCs, and PCs gave way to smartphones.
The key variable that opened the door for those disruptions was an oversupply of performance. Top-end solutions solved problems that most people didn’t have. Many computing disruptions came from decentralizing computing because consumers didn’t need the extra performance.
With AI, I don’t see that oversupply of performance yet. ChatGPT is good, but it’s not great yet. Once it becomes great, then the door is opened for AI at the edge. Small language models and NPUs will usher in that era. The question then becomes when, not if, AI happens at the edge.
As always, thanks for reading!
Disclaimer: The information contained in this article is not investment advice and should not be used as such. Investors should do their own due diligence before investing in any securities discussed in this article. While I strive for accuracy, I can’t guarantee the accuracy or reliability of this information. This article is based on my opinions and should be considered as such, not a point of fact. Views expressed in posts and other content linked on this website or posted to social media and other platforms are my own and are not the views of Felicis Ventures Management Company, LLC.
 | A guest post by
|
This was not just informative but so well written. You're an inspiration.
Question: Nvidia is generations ahead of the startups. You commented on the path to AI on the edge- what will be the evolution of compute intensive, parallel processing training?
Seems like the big winner in lots of different scenarios is Taiwan Semiconductor. The risk, of course, is military action by China.