
A Primer on Data Warehouses
History, Technology, and Market Overview of the Data Warehousing Space

I consider this my second primer in the data space (the first one can be found here), with a number of follow-up articles planned (data lakehouses, databases, data catalogs). My goal for this article is twofold:
Provide an overview of the history, technology, and trends in data warehousing.
Provide an entry point for readers to dive into specific investments they find interesting.
While I’m discussing “data warehouses” in this article, I think it’s important to call out the trend of consolidation in the data space. We continue to see the large data providers transition to platform approaches. They don’t want to own one piece of the data pie, they want to own all of it.
Because of this, data warehouses can be integrated into broader data platforms. Architectures like data warehouses and data lakehouses are closely tied; lakehouses are essentially disaggregated warehouses. So, I’ll be referencing them together in the graphics I share.
I’ll be breaking down the article into:
Overview of Data Warehouses and Why Investors Care so Much
History of Data Warehousing
Overview of Technology
Overview of Markets
Trends in the Data Warehouse
As always, I like to make the disclaimer that I’m an investor studying the space. My goal is to simplify the space, look for interesting investment opportunities, and hopefully provide some value to readers along the way.
1. Overview of Data Warehouses & Why Investors care so much about Data
A data warehouse is a central repository for a company’s data. It’s optimized for analytics, traditionally business intelligence-type workloads. The benefit of having all of a company’s data in one place is being able to run analytics on the entirety of a company’s data while centralizing security, compliance, and governance in one place.
We can broadly break down the data space into sources, infrastructure, storage, analytics, and services. Data warehouses fit squarely into the storage section of the data analytics value chain shown below. Data platforms want to own the entire stack.
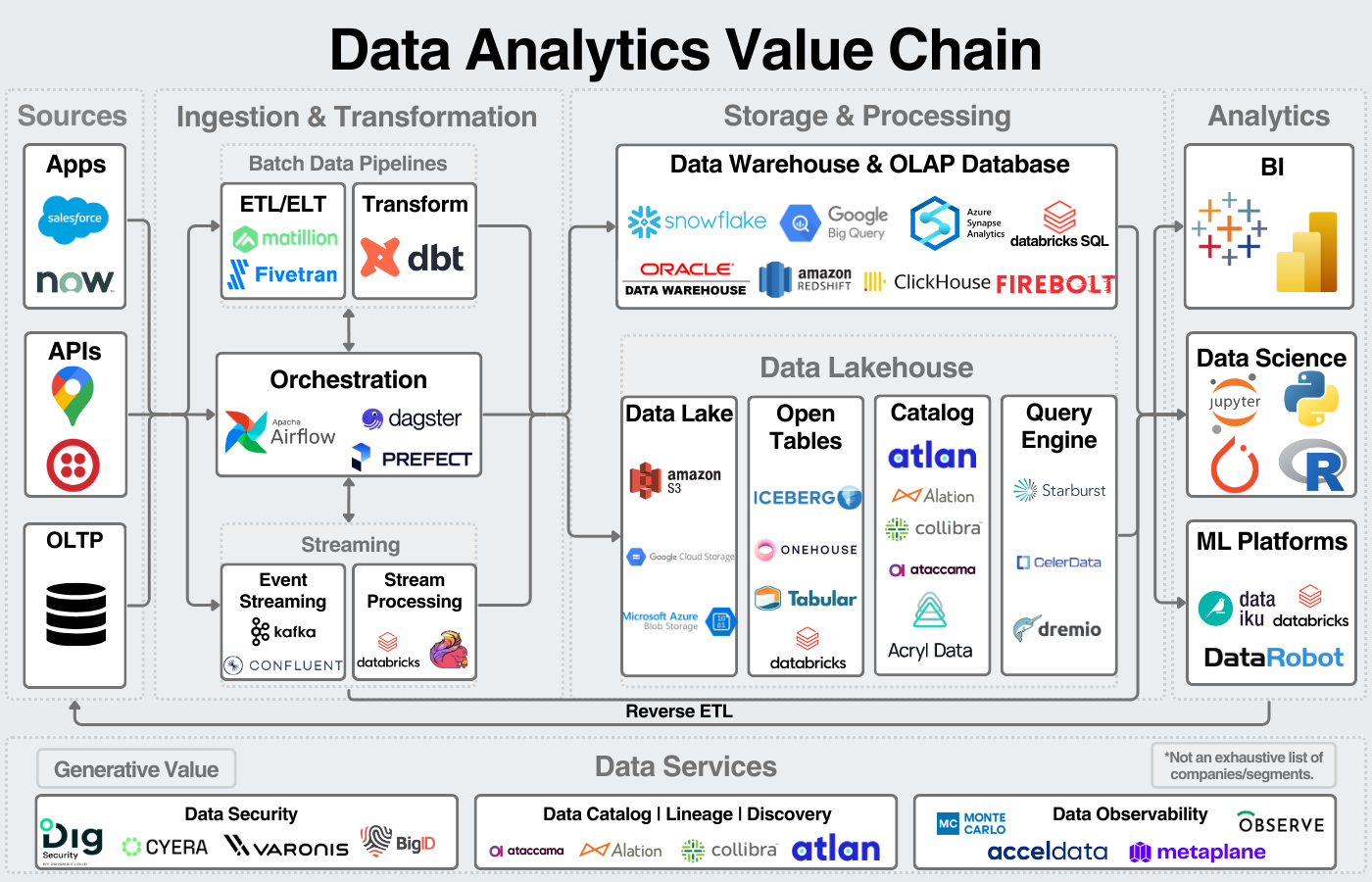
So why do investors care so much about data?
Three primary reasons:
Data’s ties to AI - As frequently stated, AI and ML models are only as good as the data they’re trained on. The data industry’s close ties to AI make it a common area of interest for AI-interested investors.
“Data is the new oil” - A company’s unique data assets give it a competitive advantage, but only if it can make use of that data. Companies will pay heavily to get valuable insights from their data. Data makes up a large line item on IT budgets, and investors will pay up for that.
Moats in enterprise data - Once a company chooses a data platform, migrating from it is a huge undertaking. A company’s applications and business processes are built on its data infrastructure; the risks in changing that backend are typically too high to justify the ROI.
In addition to these items, the data space is growing rapidly, with numerous public companies growing revenue at 20+% and a number of data unicorns in the private market with the potential to IPO in the coming years. Combined, you get a fast-growing market with high demand, clear catalysts for growth, and the potential to create a sustainable moat.
Plus, there’s a 40-year history of a few companies dominating the space.
2. History of Data Warehouses
The history of data warehouses includes the early years of SQL, the hardware-based applications of the 90s and 2000s, and the modern era of the cloud.
The Rise of SQL and the Data Warehouse
SQL (relational) databases were first commercialized in the late 1970s and early 1980s, with companies like Oracle and IBM being two of the early leaders in the space (and generating billions from SQL databases 40+ years later).
These early databases recorded business activity and stored sales, employees, and customer data. They were considered Online Transactional Processing (OLTP) databases for transactional workloads (inserting, updating, and exporting data). The relational database became so popular that companies started using it for analytics, getting insights from their data to help make business decisions.
However, these new analytical workloads were primarily read-only. This meant they didn’t need to be optimized for rapid transactions but for storing large amounts of data needing to be pulled for reporting.
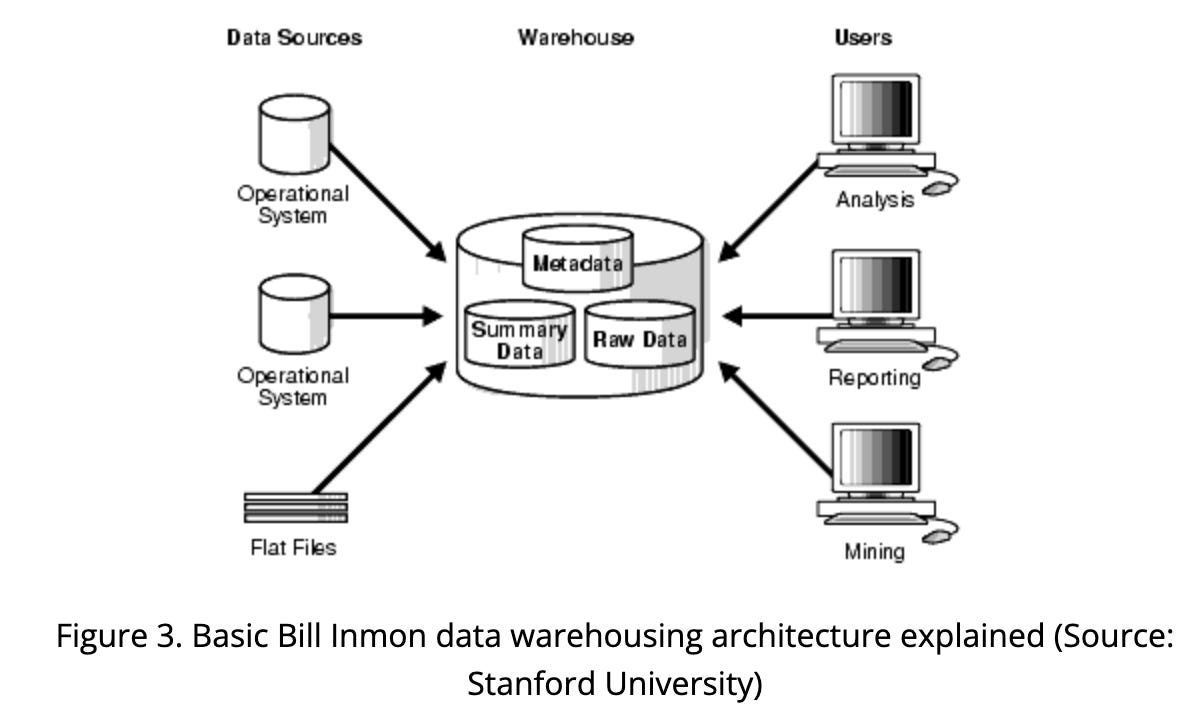
In 1985, Bill Inmon first coined the term “data warehouse” as a “subject-oriented, nonvolatile, integrated, time-variant collection of data in support of management’s decisions.” The basics of this architecture looked like this:
Hardware-based applications
Throughout the early years of data warehouses, architectures looked like this: a large server (compute) attached to disk drives (storage) with database software installed on the server. This architecture ran into problems. The major one was the compute bottleneck: once enough data was stored, the server couldn’t keep up with the query demands. This led to the rise of parallel processing (or MPP as it's called today) and the shared-storage architecture:
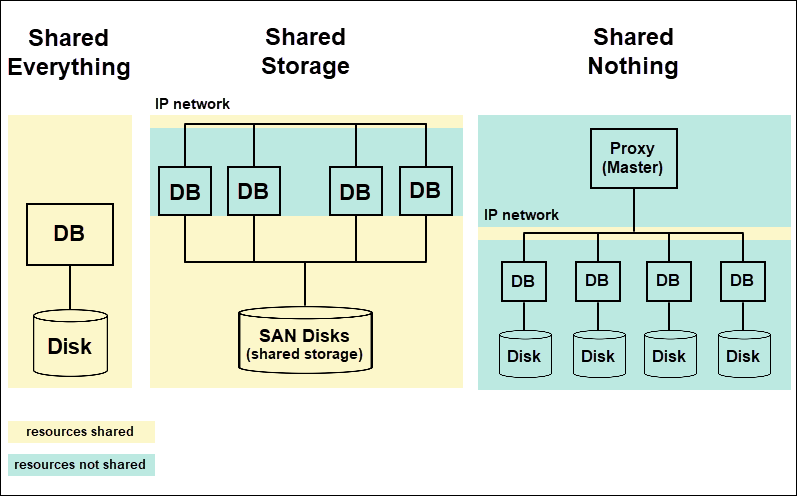
This allowed companies to use different servers with one storage location, eliminating the compute bottleneck. Unfortunately, this got complex quickly.
To simplify the data management process, companies like Teradata released hardware-based appliances that combined compute and storage (Snowflake would later re-separate compute and storage). Companies would buy this hardware in the size they needed and install it in their data centers. Companies could quickly get data warehouses up and running, but they had no flexibility around the ratio of compute and storage. They had to buy a bigger appliance if they wanted more of either one.
This started to change when AWS was released in 2005.
(More on the history of the cloud here.)
Cloud-Based Data Warehouses
If you consistently read my articles, you’ll see the cloud marked a major shift in nearly every software industry. The cloud offered “unlimited” amounts of compute and storage for data warehouses. Around the same time, Hadoop emerged, offering a big data processing framework. Companies now had three things:
An increasing amount of data from the internet and online applications.
Huge amounts of compute and storage on-demand.
A way to process the rapidly increasing amount of data (Hadoop).
This perfect storm created some of the largest SaaS companies of the cloud era and multi-multi billion dollar product lines for the hyperscalers.
Amazon Redshift was one of the early data warehouses and gained significant popularity. Snowflake, founded in 2012 and released in 2014, helped pioneer the cloud-based data warehouse by re-separating compute and storage. This meant companies weren’t constrained by either variable and could design their data architecture for their specific needs.
Throughout the 2010s, data lakes became a standard for storing large amounts of unstructured data, while data warehouses focused on storing structured data. These workloads started to merge in the late 2010s, with Databricks advertising the “data lakehouse.”
This brought us back to the original goal of data platforms: a single repository for a company’s data where it can centralize its analytics and data management.
This brings us to the landscape today with Snowflake, Databricks, Google, Microsoft, Amazon, and Oracle trying to become the single, unified data platform for enterprises and a bunch of startups trying to create a wedge in the market.
3. Overview of Data Warehousing Technology
The data warehouse consists of three layers: storage, compute, and services. Within services is the data catalog, the data's central metadata manager or organizer.
As previously mentioned, the data lakehouse is a disaggregated data warehouse, so we can visualize the components of the warehouse with that in mind:
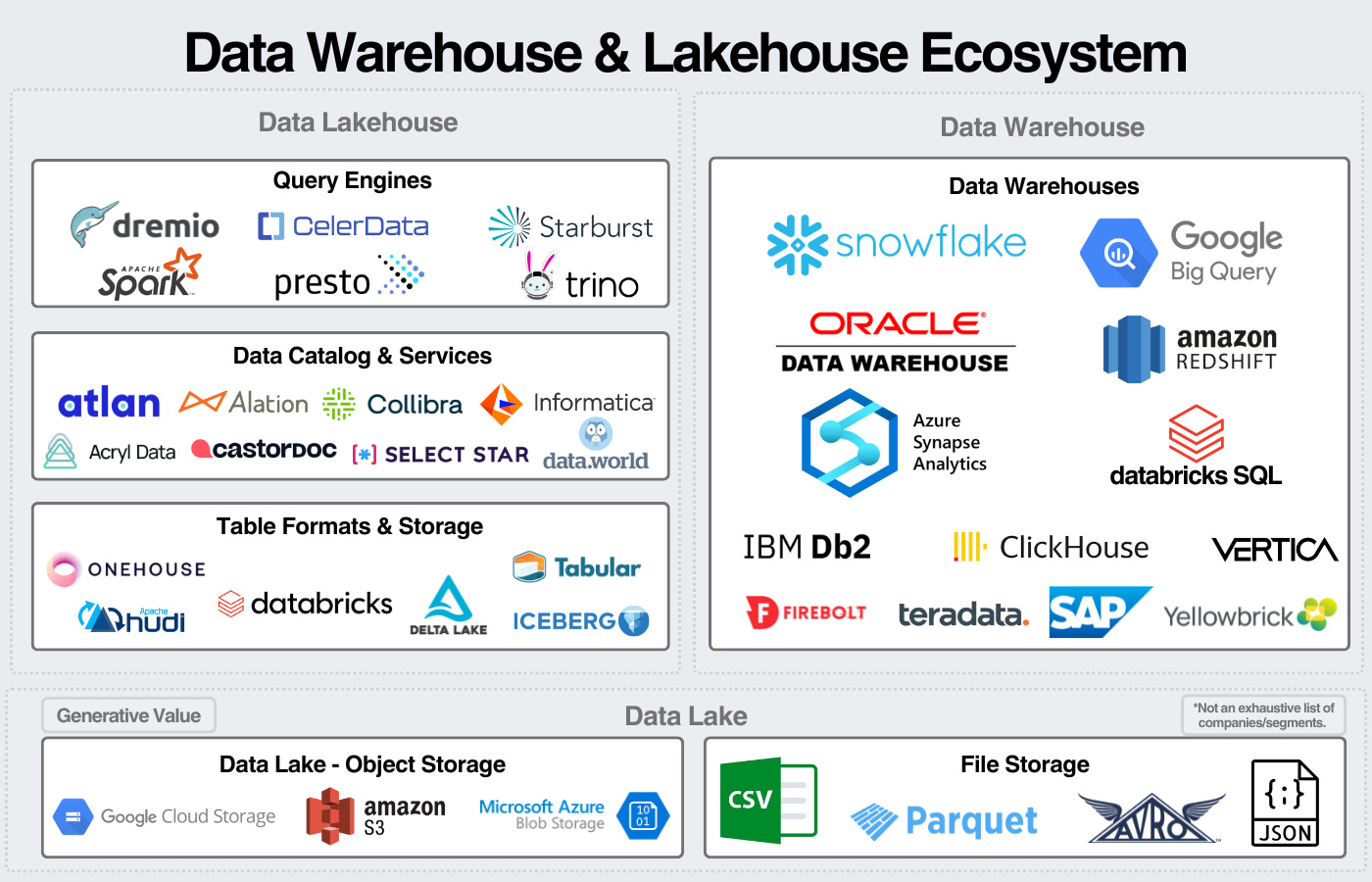
Storage
At the base storage level is typically a data lake, a central repository for a company’s data with files typically stored in cloud object storage. Companies then ingest data they want to analyze into the data warehouse. That data may be stored in temporary/staging tables while it’s cleaned, encrypted, and transformed.
Some companies use a medallion architecture for organizing their data, they may keep only the silver or gold data in the data warehouse:
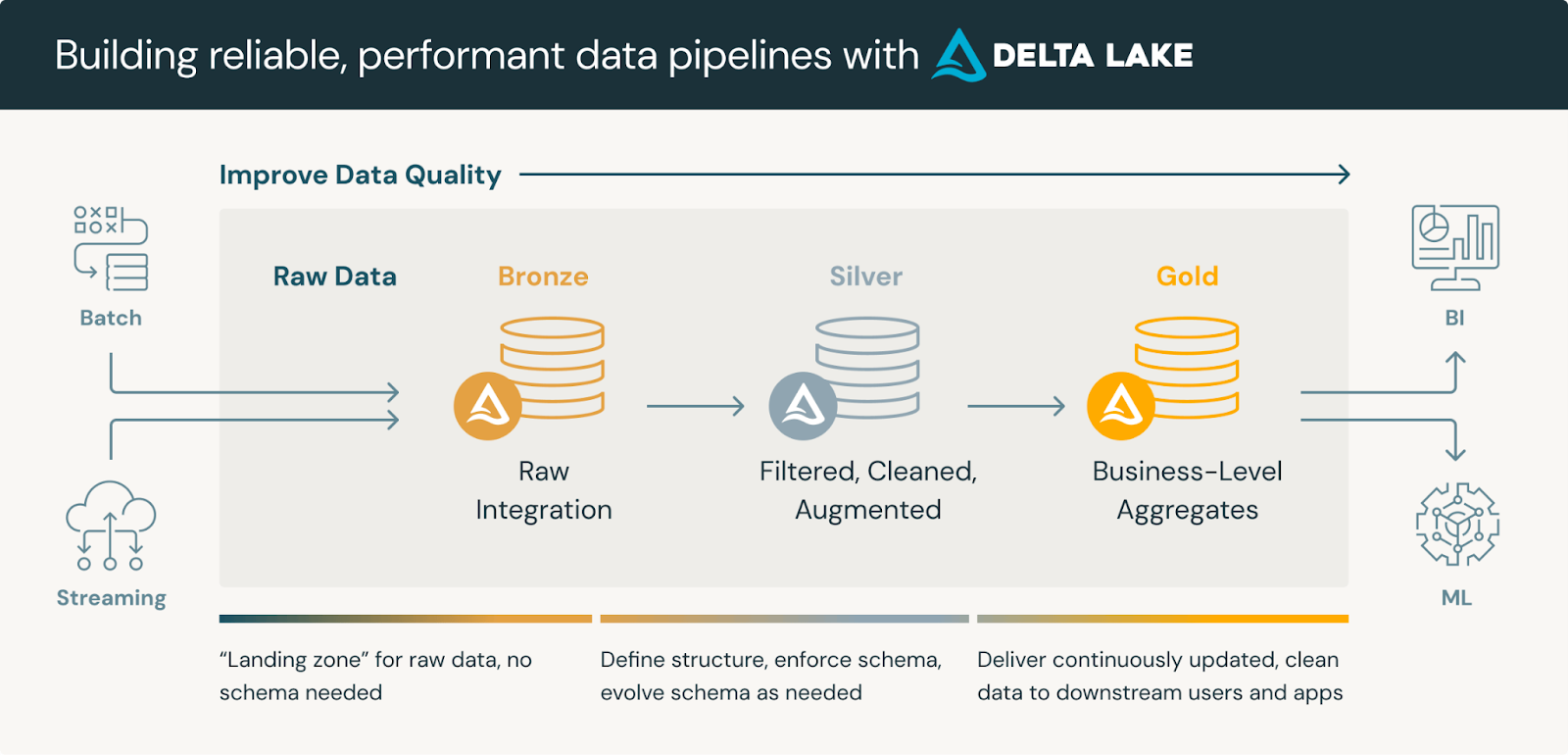
Once data is fully loaded into the data warehouse, it is stored in databases (in table formats) based on the user’s pre-defined schema. Data warehouses use different techniques to ensure large amounts of data can be efficiently stored and analyzed.
Data warehouses are also developing support for other storage types. For example, Snowflake can store semi-structured or unstructured data, read from external Iceberg Storage, or use Unistore hybrid tables to combine analytical and transactional data.
It’s important to note that storage isn’t the revenue generator for data warehouses, Snowflake only earns 10-11% of their revenue from storage.
Compute
A much larger % of revenue comes from compute, or query processing. The basics of querying are built around a query engine, the software that executes queries on the database. When a user runs a SQL query, a query engine processes the command on the backend, pulls the data, and returns it to the user.
This is typically done through clusters of compute resources, based on cloud virtual machines, with CPU, memory, and storage to perform operations. For example, Snowflake calls their compute clusters “virtual warehouses.” Customers have to create virtual warehouses and then use credits for the processing power used by those virtual warehouses.
Data warehouses will either develop their own query engine or use an open-source query engine like Trino or Presto. Google uses a software called Dremel for their query processing (or at least they did up until 2021). Dremel provided inspiration for other open-source tools like Apache Drill and Apache Impala. For heavy compute-intensive workloads like machine learning, Spark is typically used as the processing engine (one reason why Databricks is tied so closely to AI/ML).
Data Services
The most important service to the data warehouse is the data catalog, an inventory of a company’s data.
Most major data platforms also offer some combination of the following services as well:
Data Observability: monitoring data for data pipeline or quality issues; also monitors if data has been removed without permission.
Data Security: classify, encrypt, and ensure data isn’t stolen from an organization.
Access Control: ensuring only authorized users have access to data.
Data lineage: tracking data as it flows through an organization
Data governance/compliance: implementing policies to ensure data is used as intended and compliant with regulations.
Most of these services are closely related, and their core goal is organizing and securing a company’s data.
4. Data Warehousing Market
The data warehousing market has three main categories: data platforms, hyperscalers, and pure-play analytical databases/warehouses.
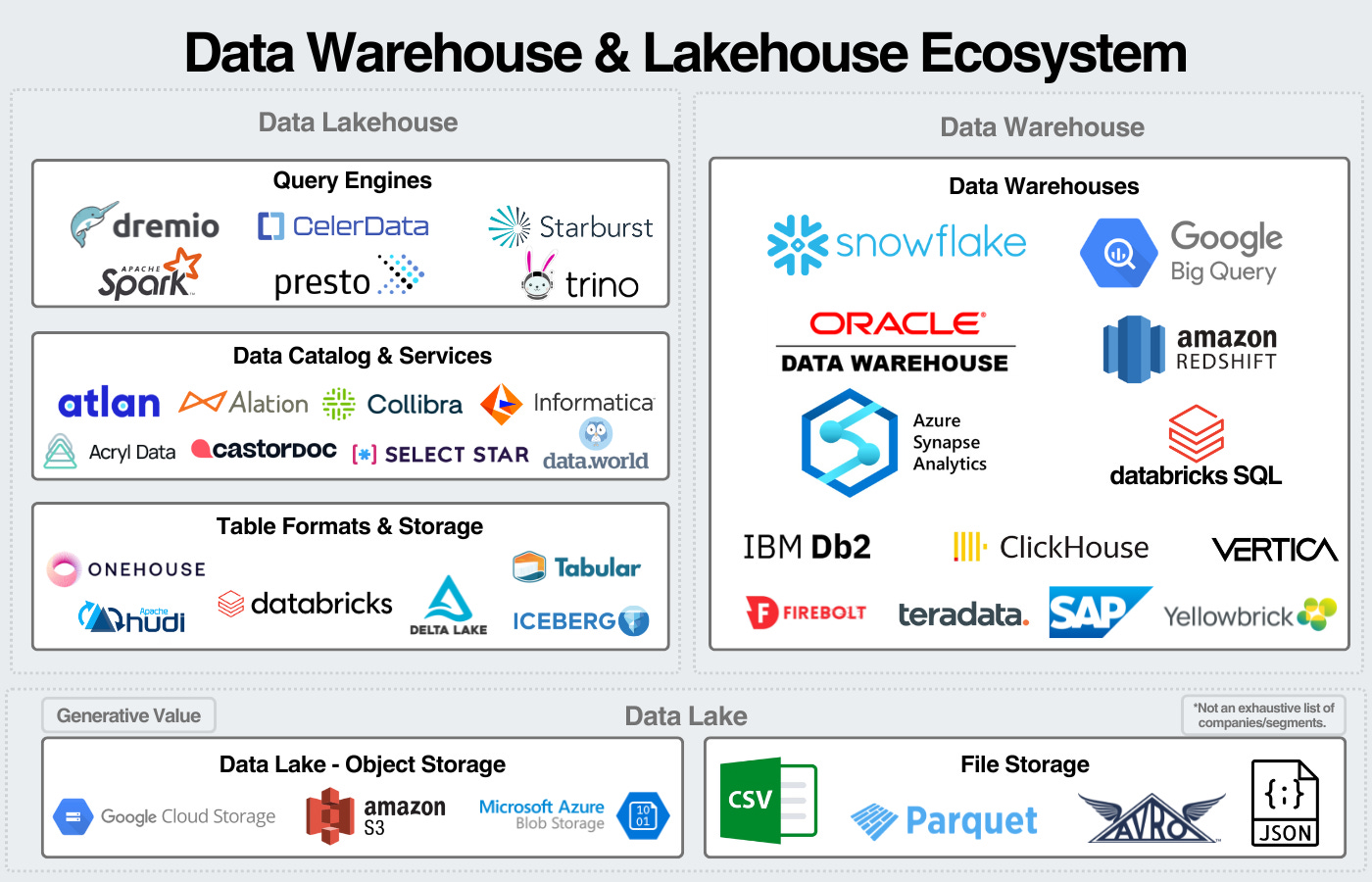
Data Platforms - Snowflake and Databricks
Snowflake is undoubtedly the defining company of the cloud data warehouse. They helped pioneer the modern data warehouse, growing into one of the most successful SaaS companies ever. They offer best-in-class usability and an integrated offering not unlike an Apple of data warehouses. Over the last few years, they’ve expanded into a fully-fledged data platform offering support for data engineering, unstructured data, data ingestion/streaming, data governance, AI/ML workloads, and application-building.
Databricks, on the other hand, is a relatively new entrant to the data warehousing market. Databricks SQL makes up an estimated 17% of Databricks’ revenue, growing 100% YoY.
Historically, Databricks and Snowflake didn’t compete significantly on core use cases. Snowflake was used for data warehousing and Databricks was used for data engineering & AI/ML. That was inevitably going to end.
In 2020, Databricks announced their vision for the lakehouse - bringing all the benefits of the data warehouse to the data lake. At first, most thought this was a marketing scheme. Somewhat incredibly, Databricks has made this vision a reality and many companies are adopting this architecture. This trend signaled the strategies of Databricks and Snowflake were on a collision course with Snowflake wanting to move into data lakes and Databricks wanting to move into data warehouses.
Both are attempting to do that, putting them on an increasingly competitive track - and one that will help define the coming years of the data industry.
Hyperscalers
Data products are one of the largest product lines for the hyperscalers. They pose a unique competitive dynamic to the cloud SaaS vendors. Since they own their own data centers, they immediately gain a marginal cost advantage over SaaS companies like Snowflake. The cloud SaaS vendors have to be meaningfully better than their hyperscaler alternatives to justify their higher price to customers.
AWS’ data warehouse offering is Redshift (interestingly, the name came from shifting off of Oracle). It was the leading cloud data warehouse in the 2010s, and is still heavily used. However, there’s mixed sentiment on Redshift. AWS has a close partnership with Snowflake, so they benefit from both Redshift and Snowflake adoption.
Microsoft’s specific data warehouse offering is Azure Synapse, but their focus is on Microsoft Fabric which is a lakehouse-centric architecture. Fabric is a SaaS offering integrating all of Microsoft’s data offerings in one place, built on one data lake (OneLake). They don’t have plans to deprecate Synapse, but Fabric is the future of Microsoft data.
GCP’s offering is Google BigQuery. GCP is well-regarded for their data & AI offerings, but has lost momentum in 2023 (or at least lost marketing momentum to Microsoft/OpenAI). Anecdotally, when I talk to data engineers, most speak highly of BigQuery; Google has excellent technology, but hasn’t marketed it well over the last two years.
Oracle was one of the first commercial relational databases and has maintained a leadership position in the industry for over 40 years which is a pretty incredible feat. Oracle has offered a number of data warehouses over the years, and currently markets Oracle Autonomous Data Warehouse. Oracle’s primary advantage is their installed user base of Oracle database and Oracle data warehouse on-prem. Their goal is to upsell those customers on migrations to cloud-based versions hosted on any cloud provider but ideally Oracle’s cloud infrastructure.
Startups, Open-Source, & Analytical Databases
I won’t dive into all the players here, but a number of startups are taking on the data warehousing market. Most of them are focused on being analytical databases, and not becoming fully-fledged data platforms (for now). Some startups include ClickHouse, Firebolt, and MotherDuck. Open-source options include ClickHouse (again), Rockset, Apache Doris, Apache Druid, and DuckDB (foundation for MotherDuck).
In theory, the analytical database market should grow with the adoption of the data lakehouse. If companies disaggregate their data warehouse, then they will want to choose a database optimized for SQL analytics for their BI workloads. The major challenge will be convincing customers to use a specialized analytics database versus the platform offerings from the large data providers.
5. Trends & How I see the Market
I see three trends driving the analytical data storage market: “platformization”, merging of lakes and warehouses, and open-source. I’ll do you one better and consolidate it into one sentence: Companies are looking to consolidate their data storage and analytics on one platform, with as much open-source support as possible.
If we ask why this is happening, we can return to the original purpose of the data warehouse: to have one central repository to run your company’s data storage and analytics.
The data ecosystem right now is too fragmented to deliver that vision, so companies are racing to provide it.
And what about open-source? Companies want complete control over their data. Managed open-source options don’t always provide complete control, but they do provide buyers with peace of mind.
Finally, I like to end these articles with some commentary on how I view the industry.
These are completely my opinions, and should be considered as such.
For my specific public investing strategy, I want to be very confident in the competitive advantages of those companies. I want to be able to clearly see the sustainable advantages that will play out over a 5-10 year period resulting in increasing profitability and returns on capital. It’s hard for me to see that in public data companies. Ultimately, competition eats away profits, and there’s unbelievable competition in the data space from hyperscalers, startups, data platforms, and open-source tools.
On the other hand, when I think about investing in early-stage companies, the risk-reward equation is different. I want to deeply understand the clear problem they’re solving and why customers are willing to pay for that problem to be solved. Many problems still need to be solved in the data space, and that keeps me excited about the industry.
My next article will be an accompanying article on the data lakehouse. As always, thanks for reading!
Disclaimer: The information contained in this article is not investment advice and should not be used as such. Investors should do their own due diligence before investing in any securities discussed in this article. While I strive for accuracy, I can’t guarantee the accuracy or reliability of this information. This article is based on my opinions and should be considered as such, not a point of fact. Views expressed in posts and other content linked on this website or posted to social media and other platforms are my own and are not the views of Felicis Ventures Management Company, LLC.
Love your work. You should come on my newsletter for a guest post
Uh, kind of skipped over the Ralph Kimball contributions as defined in The Data Warehouse Toolkit books from 1996 on. The idea of dimensional models and star schema is rather important.