


Nvidia: Past, Present, and Future
A deep dive on Nvidia's history, business and technology today, and the future outlook for the business

"My will to survive exceeds almost everybody else's will to kill me." - Jensen Huang
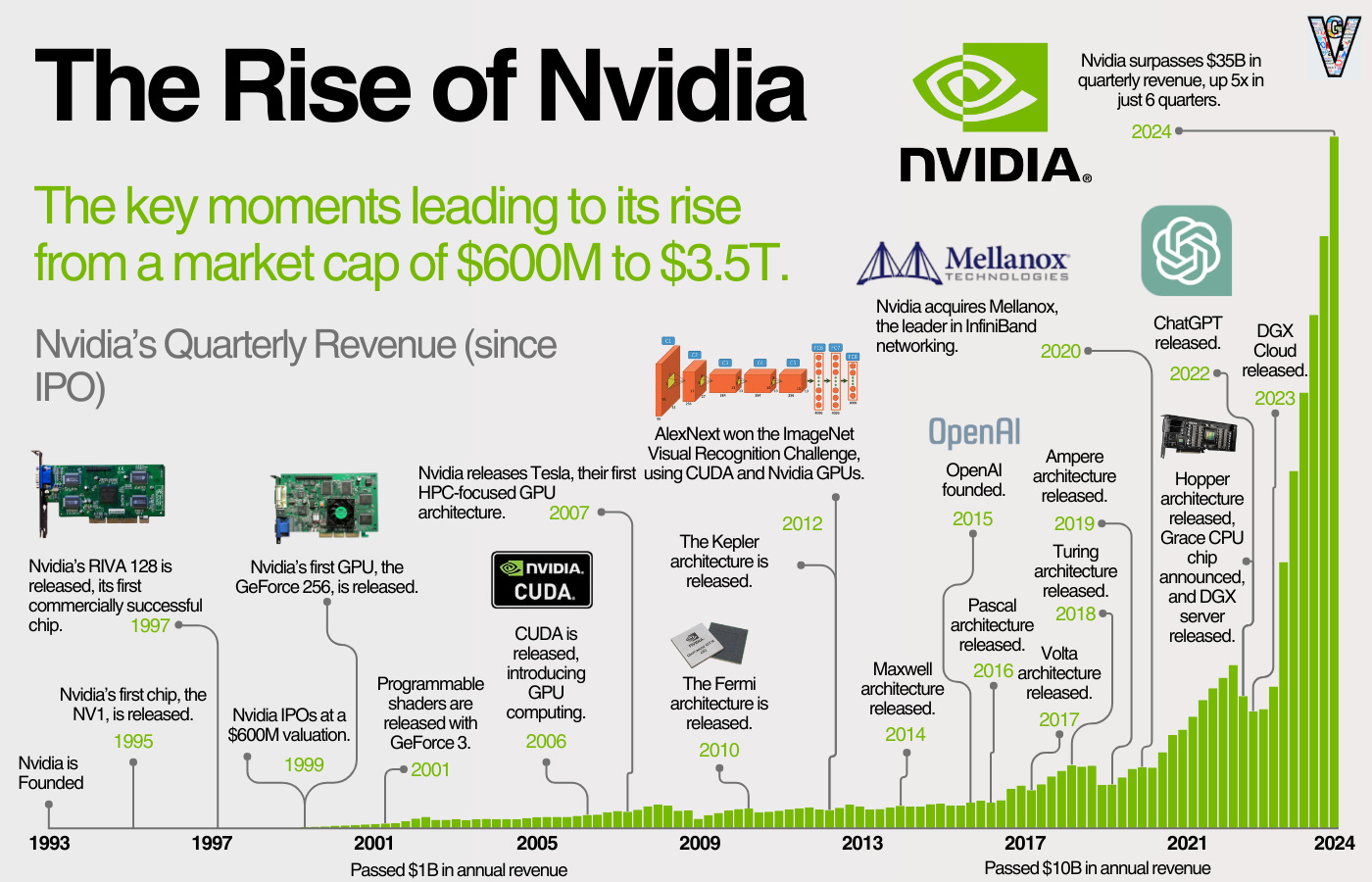
30 years ago, Jensen Huang founded Nvidia. Out of nearly 100 graphics card companies founded within a few months, Nvidia rose to the top.
Over the next 30 years, Jensen and Nvidia would build out their dominance in GPUs, enable general-purpose computing on those GPUs with CUDA, and develop systems (networking, servers, software) around those two offerings to become the most important high-performance computing company in the world. When the ChatGPT moment hit in 2022, their dominance became clear.
Throughout those 30 years, though, they’d nearly go out of business in the late 90s and saw multiple 50% drops in share price.
This is the story of how Nvidia became the biggest beneficiary of the AI boom. We’ll cover how we got here, the key decisions along the way, lessons for investors and founders, and what the outlook looks like moving forward.
After a year of focusing on industry deep dives, I’m re-introducing company deep dives to the newsletter. Feel free to shoot me a message with thoughts on the format. As always, thank you for the support, onward and upward.
1. The History of Nvidia
Before we look at the history of Nvidia, there’s some important context on Jensen's vision for the last 25 years. The story of Nvidia is the story of the rise of accelerated computing. CPUs have been the dominant computing architecture for decades. Developers write software (instructions) for CPUs, and the CPUs process those tasks sequentially (one after the other). CPUs continued to get faster via Moore's Law, which moved computing performance forward.
The idea for accelerated computing is that you can offload tasks from the CPU and run them on GPUs. GPUs can process tasks in parallel, or at the same time, instead of sequentially. Essentially, more than one brain can be on the computer. If you can break down tasks into many small tasks, then the CPU can become just the orchestrator while the GPU does the actual computing.
Nvidia started building towards this vision in 1999, with the launch of the first GPU. For the next 23 years, they'd go on to release features making the GPU more powerful and more programmable. They saw the AI movement early and started building the hardware and software ecosystem to support it. By the time the ChatGPT moment hit, Nvidia had a near monopoly on the picks and shovels of the AI gold rush.
Much of this section comes from Acquired’s incredible series on Nvidia, I highly recommend it and will continually reference it.
a. Jensen’s Early Years
Jensen's first trip to the US was by himself, at 9 years old. His parents had decided they wanted their kids to grow up in America but didn't have the money to send the entire family over. The only school they could find was Oneida Baptist Institute in rural Kentucky, a reform school.
As our friends at Acquired describe,”Jensen's roommate, when he shows up as a 9-year-old, is a 17-year-old kid who had just gotten out of prison and was recovering from 7 stab wounds that he got in a knife fight.”
Jensen would get an electrical engineering degree from Oregon State and start at (none other than) AMD as a PM. He’d then join LSI Logic as a PM, working with the co-founder of Sun Microsystems. At the time, TSMC hadn't been founded yet, and the IDM was the primary business model for semiconductor companies. They owned both the design and manufacturing of semiconductors.
When TSMC was founded in 1987, it opened the door for companies to focus on just the design of chips and outsource manufacturing. It was as disruptive of a business model as there is, significantly lowering the barrier to entry to chip development. Within a few years, Nvidia would take advantage of this model.
b. Nvidia’s Founding, Fundraising, and Early Challenges
In the early 90s, the PC wave was in full swing, and there was a huge demand for graphics. The CPU wasn't situated to handle high-end graphics, as graphics were too compute-intensive and parallel in nature (loading pixels at the same time). So, companies started to see the value of offloading those workloads to a separate graphics card.
Chris Malachowsky and Curtis Priem, engineers at Sun Microsystems, saw this, went to Jensen, and suggested teaming up to start a company doing this. Jensen goes for it, and they found Nvidia, the very first dedicated graphics card company. Within a few months, NINETY graphics companies had been founded.
They raised their first fundraising round from Don Valentine at Sequoia: a $2M round at a $6M valuation. Nvidia would IPO at a $600M valuation, a cool 100x on that investment in a few years.
Since Nvidia wanted developers to use their chips, they needed to build out a programming standard for those chips. This included APIs, SDKs, and development frameworks. At this point, it wasn't just startups competing for this software layer. Microsoft wanted to own the operating system for every piece of hardware. They would even try to get into the cable TV business, and they'd try to get into the graphics market with an offering called DirectX.
Nvidia's early designs didn't deliver the necessary performance to compete in the market, and they were running out of money. As Jensen describes, they needed to build the best chip on the market and charge more for it than anyone else. This resulted in the RIVA 128 chip; instead of facing bankruptcy, they saw huge commercial success with this chip. Jensen describes this here:
“Remember, RIVA 128 was NV3. NV1 and NV2 were based on forward texture mapping, no triangles but curves, and tessellated the curves. Because we were rendering higher-level objects, we essentially avoided using Z buffers. We thought that that was going to be a good rendering approach, and turns out to have been completely the wrong answer. What RIVA 128 was, was a reset of our company.
That time—1997—was probably Nvidia’s best moment. The reason for that was our backs were up against the wall. We were running out of time, we’re running out of money, and for a lot of employees, running out of hope. The question is, what do we do?
Well, the first thing that we did was we decided that look, DirectX is now here. We’re not going to fight it. Let’s go figure out a way to build the best thing in the world for it.
We also chose a cost point that is substantially higher than the highest price that we think that any of our competitors would be willing to go. If we built it right, we accelerated everything, we implemented everything in DirectX that we knew of, and we built it as large as we possibly could, then obviously nobody can build something faster than that.”
c. Nvidia sees commercial success
At this point, the business takes off. By 1999, Nvidia had $370M in revenue. By 2002, they had $1.9B. This was all driven by consumer demand for PC gaming graphics. They were willing to pay for top-tier graphics.
In 1999, Nvidia released the first GPU. The vision became more clear at this point - they wanted to create a new computing architecture, to the point where Jensen considered calling GPUs "GPGPUs” or General Purpose GPUs. The power of GPUs is their ability to run parallel operations. Developers can write software to run computing tasks at the same time instead of sequentially.
In 2002, Nvidia released the GeForce 3, which supported a feature called "programmable shaders." This essentially allowed developers to write software for the GPU to control exactly how lights and colors are loaded onto the display. This was a major step in the direction of accelerated computing because it allowed developers to write software directly for the GPU instead of using the CPU as a middleman.
d. The Launch of CUDA and Accelerated Computing
All of this led up to one of the most important launches in Nvidia's history: the launch of CUDA. Nvidia's Compute Unified Device Architecture was released in 2006. CUDA is essentially a 3-piece computing platform to enable developers to write software that can be executed on GPUs. The challenge with GPUs is writing logic that runs in parallel, so CUDA provides varying levels of abstraction to make GPU programming easier.
It's made up of three parts: a programming language, an API, and libraries. The programming language is an extension of C/C++ designed specifically for GPUs. It allows developers to write kernels (functions that execute on GPUs in parallel), organize kernels, and manage memory access.
The next level of abstraction is the CUDA APIs, which have pre-built functions that allow other pieces of software to interact with the GPU. For example, cudaMalloc() would allocate a set amount of memory from the GPU to a specific task.
Finally, the highest level of abstraction is CUDA libraries, which are collections of pre-written code for specific industries or use cases. cuDNN is an important library for deep neural networks. Nvidia has libraries for healthcare, physics, genomics, data science, and various AI workloads.
Nvidia then released the Tesla architecture in 2007, which included the first CUDA-compatible GPUs. Every GPU Nvidia has available would be CUDA-compatible. Nvidia started investing in CUDA so that GPUs could become true general-purpose computers. But through the mid-late 2010s, Nvidia would still be primarily a gaming company.
Jensen believed in this world where AI would be revolutionary, but it didn't come to fruition for years. In 2008, Nvidia's stock dropped by 80% and people were questioning the future of the company. Really, from 2007-2015, the company didn't grow that much.

So, in this period, you really had to believe in this future application of high-performance computing to invest in the company. You had to believe in it before seeing real revenue traction, which was hard to do.
e. The Rise of Deep Learning
The deep learning movement today traces back to a computer science competition called ImageNet, with the goal of using AI to classify images. This was led by “the Godmother of AI” named Fei-Fei Li. (Li recently started a company called World Labs, which aims to model the physical world).
In 2012, a team from the University of Toronto crushed any other prior entry to the competition. Neural networks had been known for decades before this breakthrough, but they were so computationally intensive that people assumed it would take years for CPUs to improve to the point where they could run them. The team distributed training across just two GPUs.

Who was on the team? Ilya Sutskever (former Chief Scientist at OpenAI, current founder of Safe Superintelligence), Alex Krizhevsky, and Geoff Hinton (the "Godfather of AI"). Jensen would meet Ilya Sutskever, Geoff Hinton, Yann LeCun, and Andrew Ng, among others, at AI conferences, and was convinced of the future of this movement.
Ilya would co-found OpenAI in 2015 with Elon Musk and Sam Altman. Then, in 2017, the 'Attention is All You Need' paper came out of Google, highlighting transformer-based architectures. The basic idea of these architectures is that the model can look at all of its inputted data as context before outputting a prediction.
In June of 2018, OpenAI released GPT-1. The key breakthrough here was the ability of the model to learn just by giving it data.
As the Acquired team said, "You can learn what the data means from the data itself…It's like how a child consumes the world where only occasionally do their parents say, no, no, no, you have that wrong. That's actually the color red. But most of the time they're just self-teaching. By observing the world."
There's also an interesting discovery here of scaling laws, which say that the more compute, the more data, and the bigger the model is, the better it is. What does this mean? Companies are going to need A LOT of GPUs. At this point, Nvidia has GPU dominance, they have the software ecosystem to support the GPUs, and now they need these markets to grow to take advantage of those assets. The stars are starting to align.
Nvidia had these stars aligning for the AI movement, they just needed the market to keep growing. For a brief while, they got a shot in the arm from crypto. Cryptocurrency requires "proof of work," which essentially runs calculations to verify transactions and add them to blockchains. Well, GPUs are great for lots of simple tasks, so Nvidia was perfectly positioned for this. They got a boost in revenue; but throughout this, they kept their eyes on AI.
f. Nvidia Becomes a Data Center Company
There’s one final piece of the puzzle that positions Nvidia so well for AI: the data center.
Up through FY22, gaming was still a larger segment than the data center for Nvidia:
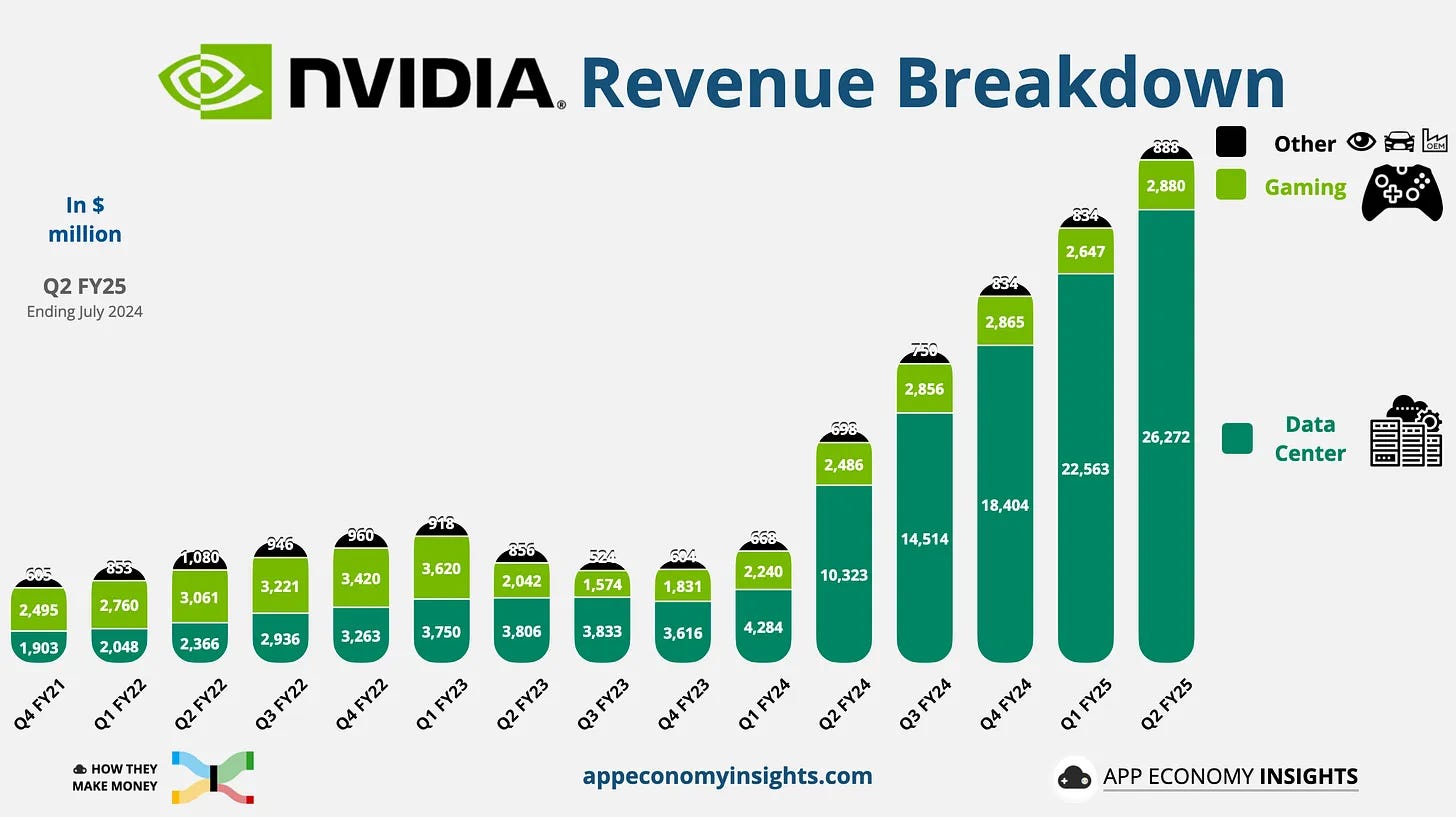
Nvidia started making data center-specific GPUs with the Tesla architecture in the early 2010s. They kept getting bigger, faster, and having more memory throughout the 2010s. In 2014, Nvidia released NVlink, an interconnect for connecting GPUs and CPUs together.
Then, in 2020, Nvidia would make one of the best acquisitions ever with their acquisition of Mellanox, an Israeli networking company. Mellanox had a near monopoly on InfiniBand, a networking technology best suited for high-performance computing. Very few use cases necessitated such high networking demands though, so it had lost steam compared to Ethernet.
AI training was literally the perfect use case for it. Because training clusters needed to scale with the size of the model (see scaling laws above), many many GPUs needed to be connected to train large clusters. This became a bottleneck as data transfer times increased latency. By buying Mellanox and integrating it into their offering, Nvidia would own the fastest chips and the fastest networking equipment.
Even better, Nvidia would integrate all of this together in one server and sell it as an integrated computer. Nvidia would pay $7B for Mellanox, and Nvidia's networking business is now over a $12B annual run rate today.
g. Nvidia Finally Sees its AI Moment
Now Nvidia has servers, networking, GPUs, and the software to run AI workloads on this equipment. They would release their Grace CPUs in the following year as well. Well, after 15 years of preparation, the market's here. ChatGPT was released on November 30, 2022. It took two months to get to 100M users:

Microsoft would invest $10B in January of 2023, OpenAI would raise tens of billions of dollars, OpenAI would be valued at $150B+, and Nvidia's revenue would go on to 5x over the next 6 quarters.
Of those hundreds of billions of dollars flowing through the AI ecosystem, one company would accrue, by far, the most value: Nvidia.
2. Nvidia in the Present
Summarizing Nvidia’s current state, they are currently on a revenue rocketship waiting to see when their ascent will slow. They dominate AI data center hardware and are investing aggressively in AI software.
Disclaimer: this section focuses mostly on Nvidia as an AI infrastructure provider. It’s still one of the most important gaming companies in the world too.
The right way to think about Nvidia is as a platform to enable AI use cases. This is hardware, software for hardware (CUDA), and application infrastructure (models, inference services). The platform comes in the form of integrated hardware and software offerings, AND an increasing investment in AI-specific software offerings.
a. Hardware
We can understand most of Nvidia’s hardware offerings by looking at a diagram of one of their servers:

We have the following items making up an H100 server:
GPUs - core unit of compute.
Interconnects - NVlink connects GPUs together, sharing data, and bypassing the CPU.
Switches - NVSwitches act as the central hub for connecting GPUs to each other and to other servers.
Data Processing Units (or Network Interface Cards) - Bluefield DPUs offload tasks like network communication from the CPU. They process incoming data and route it to GPUs.
CPUs - In DGX servers, the Grace CPUs still handle much of the general-purpose tasks of the computer. This includes resource orchestration, task management, system management, job scheduling, system monitoring, etc.
The most up-to-date roadmap we have of their data center hardware looks like this:

Put simply, lots of new hardware, with large upgrade cycles coming every two years. The Blackwell line of chips started to ramp last quarter. In 2025, we can expect the B100/B200 to become the majority of deliveries. Including servers and GPUs, Spear Invest models out ~4600 Blackwell deliveries in 2025:

Finally, we should touch on their edge offerings. As Austin Lyons from Chipstrat describes,”The benefit to companies of pushing inference to the edge is that the user pays for the AI system CapEx (device) and OpEx (electricity).”
Nvidia offers several platforms for specific edge AI use cases: Jetson (edge hardware for robotics and embedded AI), Clara for medical devices, and Drive AGX for autonomous vehicles.
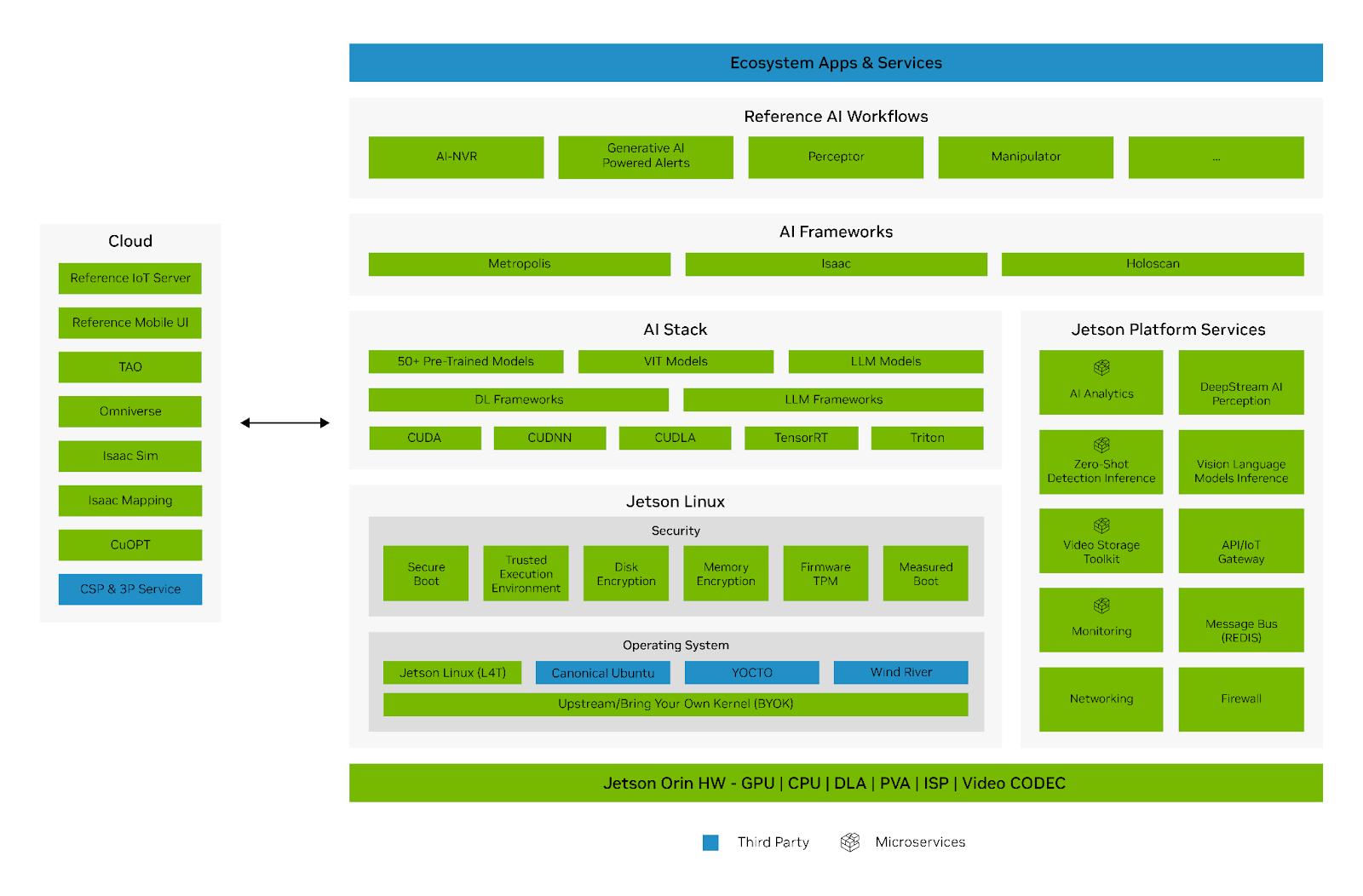
Jetson is a series of System-on-Chips (SoCs) with GPU, CPU, and memory with the goal of being a turnkey solution for edge AI. You buy the hardware and use your existing Nvidia software (see NIMs) to run apps on the hardware.
b. Software
One of the more interesting trends in the last several quarters is semiconductor companies moving up the stack towards software. Nvidia’s been pursuing this for over a decade with CUDA, but has started to pursue this even more aggressively with AI-specific software in the last year.
Nvidia wants to provide every tool necessary to build AI applications. This includes inference services, cloud compute, models, and app development tools.
We’ve already covered Nvidia’s most important software offering in CUDA (making GPUs programmable). Summarized, CUDA offers three levels of abstraction: a programming language, an API, and libraries. Developers write threads, blocks, and kernels that parallelize commands to run on GPUs:

I’ll highlight another important software offering that’s being prioritized: Nvidia Inference Microservices or NIMs, which allow customers to build AI applications and run them on any Nvidia hardware.

If companies build apps using NIMs, they can migrate AI apps to new Nvidia hardware, regardless of which hardware. It discourages companies from switching hardware providers when they get to upgrade cycles. Don’t go through the hassle of migrating applications; just port your app over to new hardware.
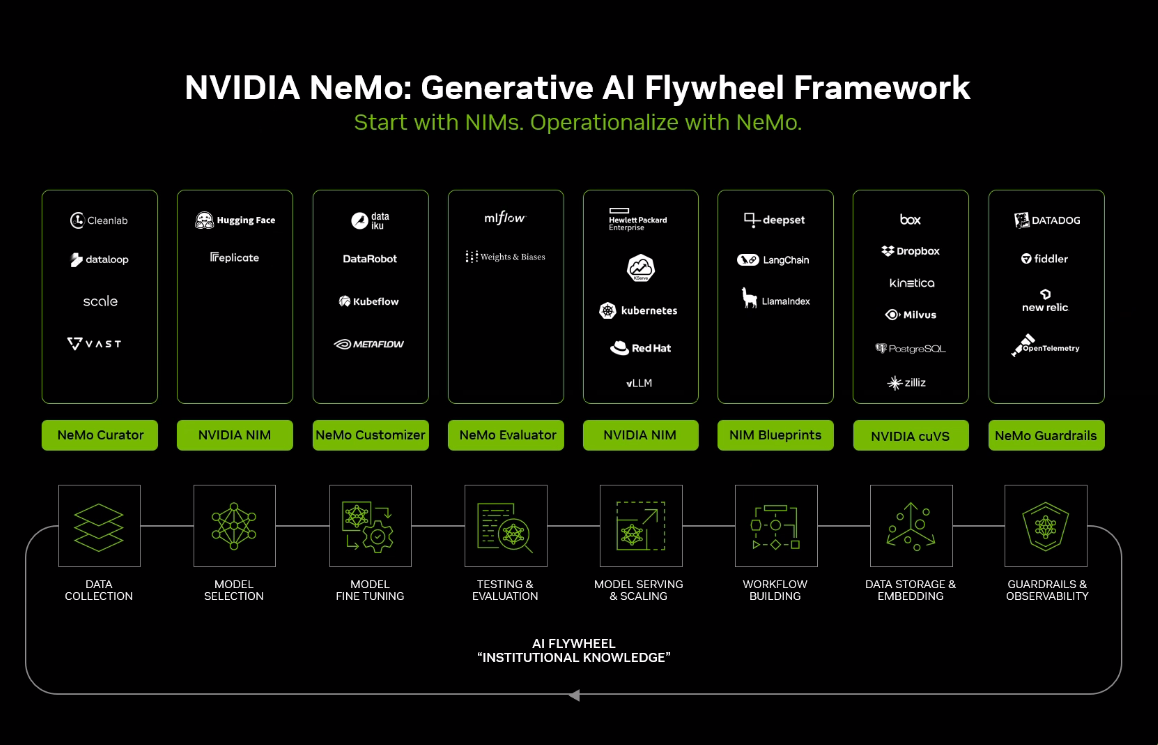
With their acquisition of OctoAI, Nvidia seems to be moving even more towards inference and AI app development. This includes Nvidia NeMo, which is Nvidia’s GenAI platform:
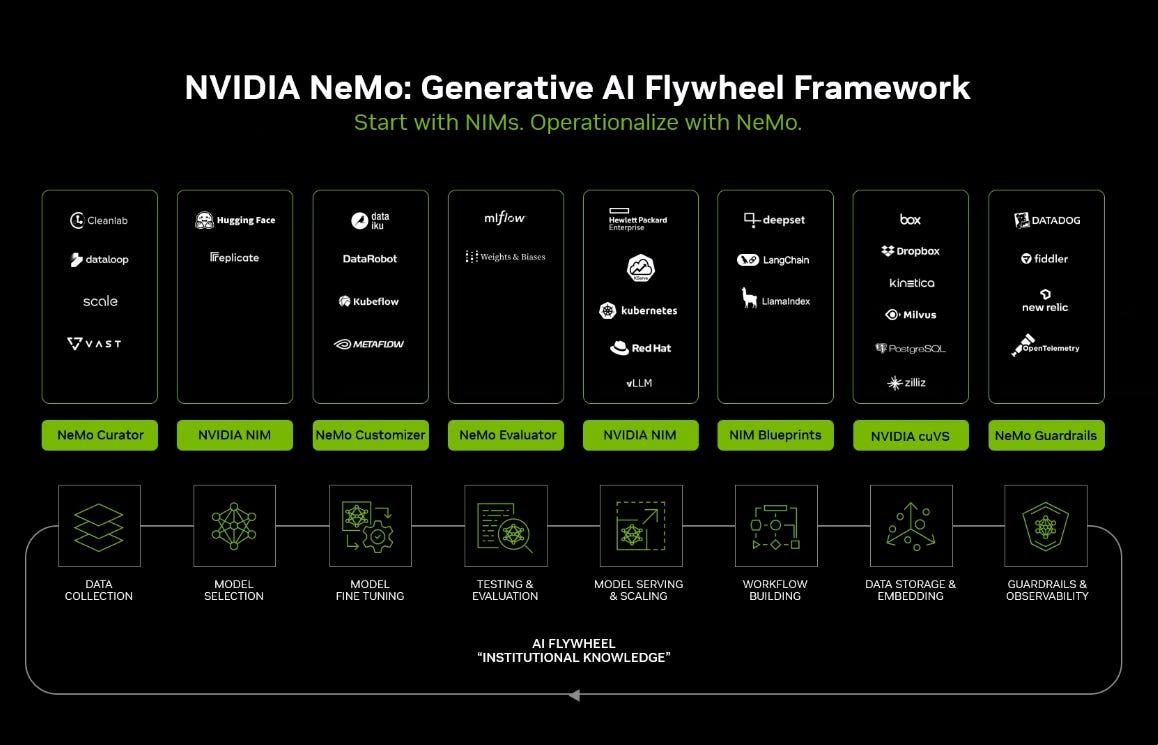
Nvidia has also developed many models themselves including language models, voice models, vision-language models, and a host of models to create agents and digital characters.
If we’re looking at all these services, we start to see, “Wow, Nvidia is looking a lot like a hyperscaler.” That’s exactly right. The hyperscalers are moving down the stack to silicon to compete with Nvidia, and Nvidia’s doing the same, moving up the stack to software.
Nvidia has their cloud offering, but we’ve yet to see their strategic direction with this product. Today, DGX Cloud puts Nvidia servers in hyperscaler data centers, and allows customers to rent out those servers. I won’t speculate on the future of Nvidia’s cloud offerings, but it’s reasonable to expect increasing amounts of competition with the hyperscalers.
On top of all this, Nvidia’s made significant investments in Omniverse, Robotics, Security, and several other industry-specific software platforms.
c. The Numbers Today
When we look at the high-level numbers, as expected, they look great. These numbers are important, but there are no surprises to be found in this data. The major risks to Nvidia come from the trends driving these fundamentals; for the most part, valuation has traded in line with fundamental growth and even got significantly cheaper during Nvidia’s meteoric rise.

d. Competition
Nvidia has four main buckets of competition:
Direct competitors in GPUs
Internal hyperscaler silicon programs
Specialized ASICs for inference and model-specific architectures
Edge AI silicon providers
To help visualize that ecosystem, see the “Chip” section of the value chain:

Nvidia’s dominant in AI training, and they’re well positioned to continue their dominance. The competition will be more intense on inference, see an explanation of why from our AI semiconductor article here:
A few key differences are particularly important with inference:
Latency & Location Matter - Since inference runs workloads for end users, speed of response matters, meaning inference at the edge or inference in edge cloud environments can make more sense than training. In contrast, training can happen anywhere.
Reliability Matters (A Little) Less—Training a leading-edge model can take months and requires massive training clusters. The interdependence of training clusters means mistakes in one part of the cluster can slow down the entire training process. With inference, the workloads are much smaller and less interdependent; if a mistake occurs, only one request is affected and can be rerun quickly.
Hardware Scalability Matters Less - One of the key advantages for Nvidia is its ability to scale larger systems via its software and networking advantages. With inference, this scalability matters less.
Combined, these reasons help explain why so many new semiconductor companies are focused on inference. It’s a lower barrier to entry.
Nvidia's networking and software allow it to scale to much larger, more performant, and more reliable training clusters. For the most part, that’s an impenetrable moat today.
Going back to Nvidia’s investments in inference and NIMs, this emphasizes why it’s so strategically important: if companies build applications on Nvidia hardware, it’s yet another layer of moat for Nvidia.
In the short-term to mid-term, Nvidia’s biggest competitive risk is from the hyperscalers. This is a dynamic they won’t be able to get away from: their biggest customers are some of their biggest competitors and have every incentive to lessen their reliance on Nvidia.
AMD continues to develop a competitive chip; but again, the bigger risk comes from the MI325X on inference. See some benchmarking here where AMD outperforms Nvidia on large and small batch sizes:

{kind=link}
Finally, AI at the edge provides the most disruptive approach (using Clay Christensen’s definition) to Nvidia. See above on why Nvidia’s invested on hardware at the edge. It reduces CapEx (device) and OpEx (power) for AI providers, it can do so at a much lower price point, and it will be significantly less functional (key component of disruption).
e. Summary of Nvidia’s Moat
Nvidia has executed incredibly well on AI, and they continue to execute. My thoughts are consistent since our AI semiconductor article:
Nvidia has sustained a 90%+ market share in data center GPUs for years now. They’re a visionary company that has made the right technical and strategic moves over the last two decades. The most common question I get asked in this market is about Nvidia’s moat.
To that, I have two conflicting points: First, I think Nvidia is making all the right moves, expanding up the stack into AI software, infrastructure, models, and cloud services. They’re investing in networking and vertical integration. It’s incredible to see them continue to execute.
Secondly, everyone wants a piece of Nvidia’s revenue. Companies are spending hundreds of billions of dollars in the race to build AGI. Nvidia’s biggest customers are investing billions to lessen their reliance on Nvidia, and investors are pouring billions into competitors in the hopes of taking share from Nvidia.
Summarized: Nvidia is the best-positioned AI company on the planet right now, and there are tens of billions of dollars from competitors, customers, and investors trying to challenge them. What a time to be alive.
There are structural challenges with the hyperscalers that are unavoidable, and Nvidia’s path forward is to continue to develop the best GPUs, AI systems, and software for hardware on the planet. Execution is Nvidia’s moat, and it has been since the RIVA 128.
3. The Future of Nvidia?
I’ll start off by quickly mentioning the risks to Nvidia’s future. The reason I’m only mentioning them is because the biggest risk to investors is that Nvidia’s already a $3.5T company. Investing is about finding mismatched expectations. Nvidia’s one of the best positioned AI companies in the world, and everyone knows it.
The risks worth mentioning:
A “digestion period” in the short-mid-term where revenue has been pulled forward from the coming years in this infrastructure buildout, and Nvidia sees slowed or decreased revenue when that infrastructure spend stops.
Disruption from the edge occurs when small models and NPUs get good enough to take a meaningful % of AI compute from the data center.
Disintermediation from the hyperscalers as they see a better TCO/performance from their own hardware.
International struggles from decreased China business due to regulations and geopolitical risk to TSMC.
On to the more exciting piece of the conversation, what the future of Nvidia looks like.
a. AI Everything
The path I see Nvidia moving towards can be summarized as “AI Everything.” Their job is to make it as easy and cheap as possible to build AI applications AND then to collect as much value from the infrastructure layer as possible. Their goal is to own every piece of AI hardware (data center, edge, networking), and that could even include acquiring a storage provider as well.
Nvidia’s investing heavily in software, they acquired an inference provider, they have their cloud service, they have models, they have CUDA, and they’ll continue to invest in software to own “the orchestration layer” of AI.
The vision seems to be clear: build apps on Nvidia software and deploy them across whatever Nvidia hardware you want.
b. Commoditize Your Complement
Nvidia’s in a win-win situation with software. They’re already doing over $1B in software revenue:
Overall, our software, service, and support revenue is annualizing at $1.5 billion, and we expect to exit this year annualizing at over $2 billion.
Even if they don’t monetize their software, they benefit. The other path for value creation of this investment in software is through commoditizing their complement.
There’s an idea in business theory called commoditize your complement. The basic idea is that a value chain acts like a water balloon. When one piece of the value chain is squeezed, the value flows to another part of the value chain.
Nvidia doesn’t need to make any money from the software layer. If they give away their software for free, they (1) further deepen their moat and (2) allow more value to accrue to the hardware layer.
c. It’s Not Just AI
Perhaps the most interesting thing about Nvidia is that they’re an AI company today, but they’re exposed to nearly every trend coming around the corner.
Believe in the metaverse? You need huge amounts of graphics processing and intelligent characters. Plus, Nvidia's built a simulation platform called Omniverse and they've trained models to digitally create humans. Believe in robotics? You need intelligent processing in the data center and the edge.
Drug discovery, chip design, simulation, digital twins, and any computationally intensive task will need Nvidia hardware. And you need software to specialize for these specific tasks. Guess what? Nvidia's spent the last decade building out CUDA with libraries for every major industry that needs high-performance computing.
Nvidia’s described themselves as an accelerated computing company, and I think that’s correct. They’ve been a defining company of the AI wave, and they could be the defining company of next waves to come.
Now, the elephant in the room is valuation. Nvidia’s valuation has been closely tied to its fundamentals, and the most important variable in those is hyperscaler chip demand; in turn, the demand for AI applications is driving hyperscaler chip demand.
The AI market is dependent on the use cases AI can solve. The use cases are there (i.e. people’s imagination on what AI can solve). The question becomes when technology can deliver on those use cases.
As always, thanks for reading!
Disclaimer: The information contained in this article is not investment advice and should not be used as such. Investors should do their own due diligence before investing in any securities discussed in this article. While I strive for accuracy, I can’t guarantee the accuracy or reliability of this information. This article is based on my opinions and should be considered as such, not a point of fact. Views expressed in posts and other content linked on this website or posted to social media and other platforms are my own and are not the views of Felicis Ventures Management Company, LLC.
Every word is gold!!!
Great job Eric! Thank you.