
The Inference Landscape
An overview of the technology, market, and trends in AI Inference

With OpenAI’s o1 announcement, inference finally peeks into the spotlight we’ve been expecting for the last year. Jensen has said things like, “Inference will be a billion times larger than it is today.” (A side note: From a number of queries perspective, that could be true. No chance this is true on revenue if inference indeed makes up 40% of Nvidia’s revenue).
With o1, inference now makes up a meaningful portion of the total model compute for the first time:

It points to a new potential scaling law, saying that the longer a model “thinks”, the more accurate it will be. Stratechery described this jump in performance well:
o1 is explicitly trained on how to solve problems, and second, o1 is designed to generate multiple problem-solving streams at inference time, choose the best one, and iterate through each step in the process when it realizes it made a mistake. That’s why it got the crossword puzzle right — it just took a really long time.
Last month, Anthropic announced “Computer Use” allowing models to interact with computers like humans. This points to increasingly complex AI applications and, in turn, increasing amounts of inference.
Two more variables make this market particularly interesting: the decreasing cost of compute and the vast amount of competition in the space.

With the decreasing cost of inference, the rapidly growing scale of the market, and the amount of competition in the space, this market provides one of the more interesting case studies in AI.
This will be a deep dive into the current state of affairs, the variables that will decide the market moving forward, and how value will likely flow through the ecosystem based on those variables.
To be clear, inference is an emerging market. The landscape is (1) very crowded and (2) rapidly changing. The best metrics we have for inference performance are 3rd-party benchmarks (if you have better data, by all means, please reach out).
1. Quick Background on Inference
As I described in my last post on AI semiconductors, inference provides a market more open to competition than training.
While training is the process of iterating through large datasets to create a model that represents a complex scenario, inference is the process of giving new data to that model to make a prediction.

A few key differences are particularly important with inference:
Latency & Location Matter - Since inference runs workloads for end users, speed of response matters, meaning inference at the edge or inference in edge cloud environments can make more sense than training. In contrast, training can happen anywhere.
Reliability Matters (A Little) Less - Training a leading edge model can take months, and requires massive training clusters. The interdependence of training clusters means mistakes in one part of the cluster can slow down the entire training process. With inference, the workloads are much smaller and less interdependent; if a mistake occurs, only one request is affected and can be rerun quickly.
Hardware Scalability Matters Less - One of the key advantages for Nvidia is its ability to scale larger systems via its software and networking advantages. With inference, this scalability matters less.
Combined, these reasons help explain why many new semiconductor companies are focused on inference. It’s a lower barrier to entry.
I’ll point out that while “inference” is broadly a term describing the actual usage of models, it’s encompassing of the various types of machine learning models. My colleague wrote about the shift in how ML has been deployed in recent years here. See the varying performance by workload here:
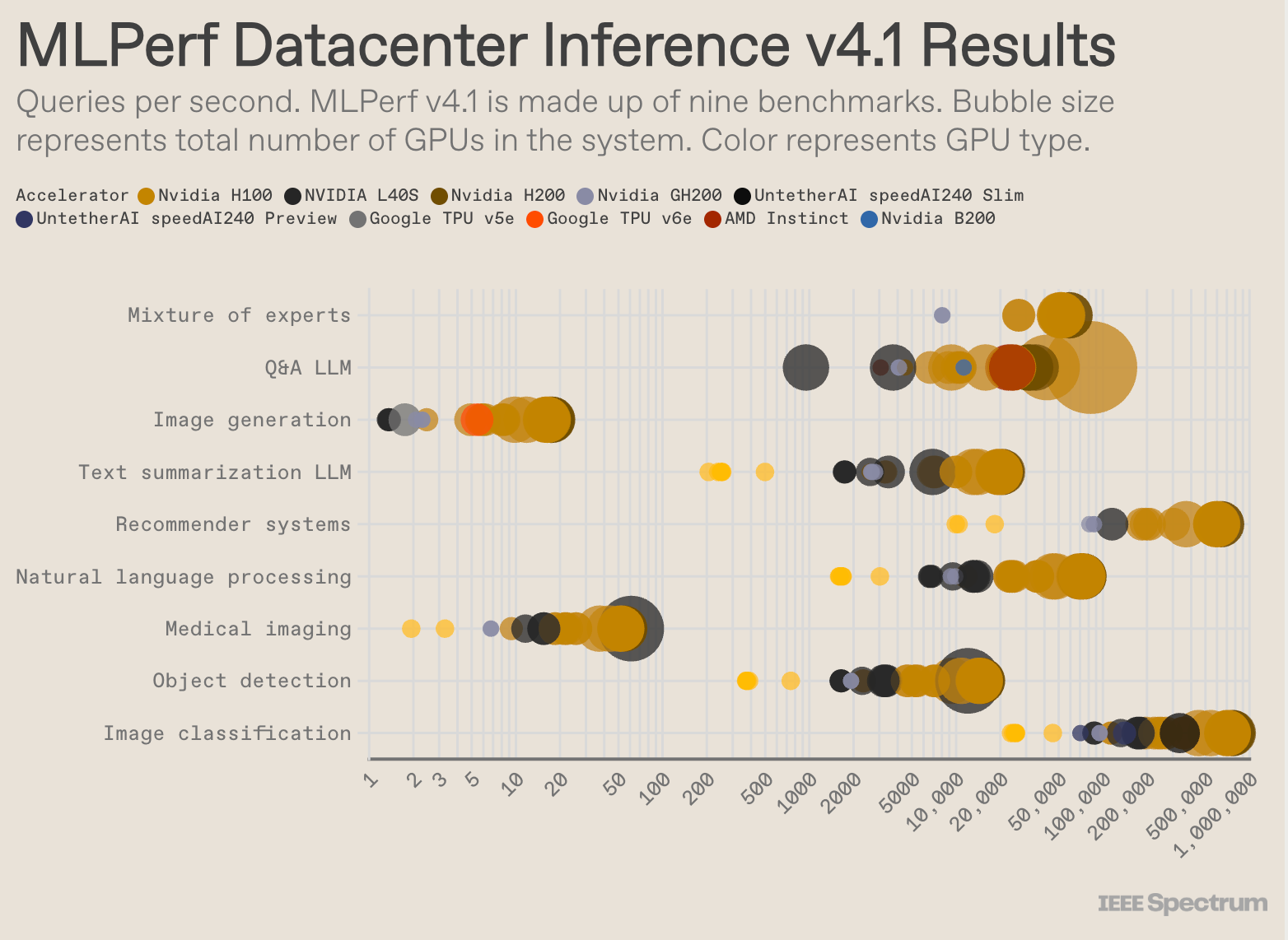
On to the competitive landscape.
2. The Inference Landscape Today
There’s no shortage of options for a company to run inference. From the easiest to manage & least customization to the hardest to manage and most customization, companies have the following options for inference:
Foundation Model APIs - APIs from model providers like OpenAI. The easiest and least flexible option.
Inference Providers - Dedicated inference providers like Fireworks AI and DeepInfra who aim to optimize costs across various cloud and hardware providers. A good option for running and customizing open source models.
AI Clouds - GPUs or inference as a service from companies like Coreweave and Crusoe. Companies can rent compute power and customize to their needs.
Hyperscalers - Hyperscalers offer compute power, inference services, and platforms that companies can specialize models on.
AI Hardware - Companies buy their own GPUs and optimize to their specific needs.
Bonus #1: APIs to AI Hardware - Companies like Groq, Cerebras, and SambaNova have started offering inference clouds allowing customers to leverage their hardware as an inference API. Nvidia acquired OctoAI, an inference provider, presumably to create their own inference offering.
Bonus #2: Inference at the Edge - Apple, Qualcomm, and Intel want to offer hardware and software allowing inference to occur directly on device.

Given foundational model APIs are straightforward (companies call APIs from the foundation model companies and pay per API call). I’ll start with the inference providers.
3. Inference Providers
Several companies have emerged to offer inference, abstracting away the need for managing hardware. The most prominent of these companies are inference startups like Fireworks AI, Together, Replicate, and Deep Infra. Kevin Zhang does a good job describing these companies here:
API-only startups like Replicate, Fireworks AI, and DeepInfra have completely abstracted away all complexity so that models are accessed via an API call. This is similar to the developer experience provided by foundational model providers such as OpenAI. As a result, these platforms generally do not allow users to customize things like selecting which GPU to use for a given model. Replicate has Cog for things like deploying custom models, however.
Meanwhile, Modal and Baseten offer an “in-between” experience where developers have more “knobs” to control their infrastructure, but it’s still an easier experience than building custom infrastructure. This more granular level of control allows Modal and Baseten to support use cases beyond simple text completion and image generation.
The clearest use case for these companies is inference for an open-source model, allowing companies to build applications with that model. The inference providers, using various techniques, attempt to optimize costs as much as possible.
Deciding between inference providers ultimately comes down to a cost/performance calculation including the cost of inference, latency (time to first token and time between tokens), and throughput (capacity to handle demand). We have some sense of price here:

Now, an interesting development over the last several months is the hardware providers moving up the stack into inference. Nvidia acquired inference provider OctoAI, presumably to offer a similar service. We can see three hardware providers offering the fastest inference on the market:

As always, benchmarks should be taken with a grain of salt. Specific setups can achieve these results, but they may not be flexible with other models or practical in production use cases.
The ROI calculation for most companies will be total cost of ownership/performance, and this is data that’s quite hard to get at this stage of the industry life cycle.
I’ll call out that the AI clouds like Coreweave, Crusoe, and Lambda all offer inference as a service as well. The hyperscalers do as well! Kevin Zhang also speculates that data platforms and app infrastructure providers could expand into inference as well:
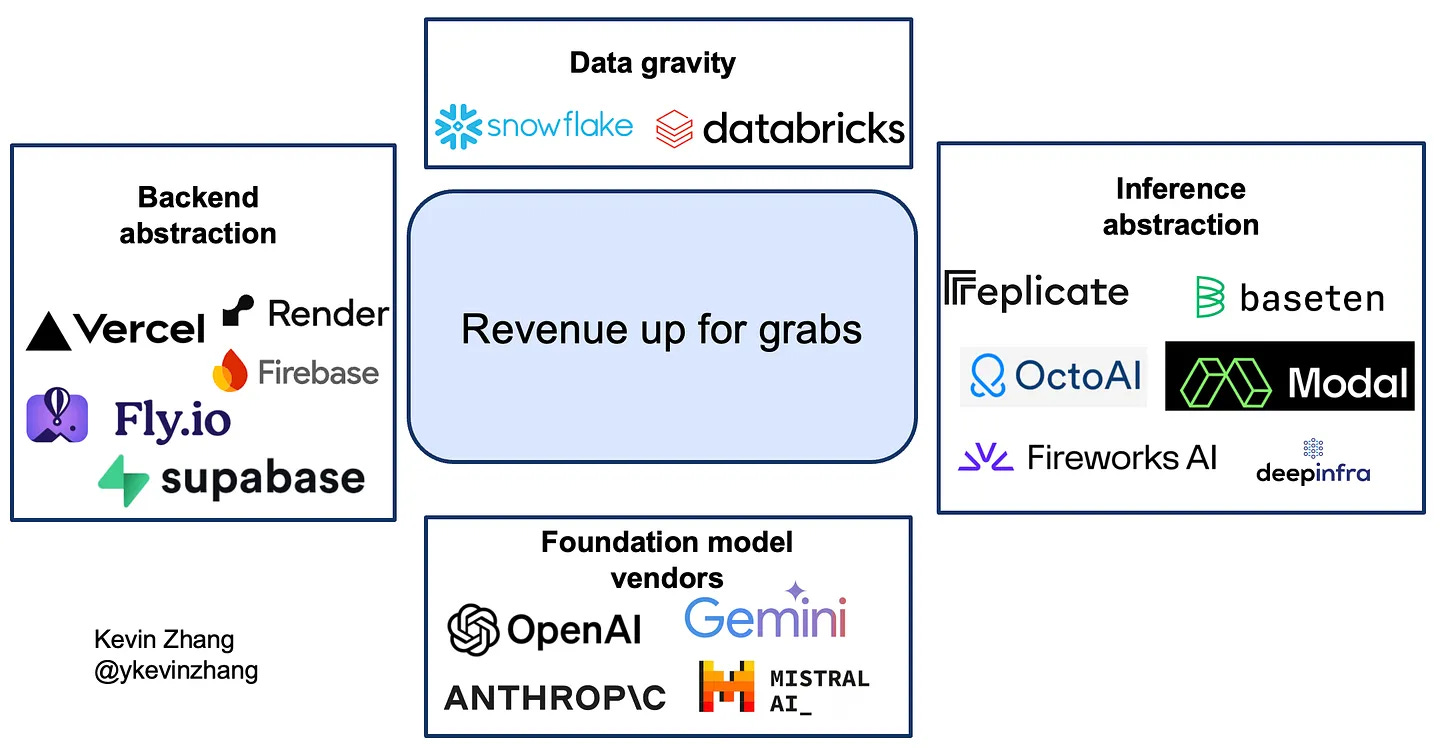
With this much competition, companies will either need to provide (1) a meaningful architectural difference, (2) developer tooling on top of the inference solution, or (3) cost benefits from vertical integration to create meaningful differentiation.
4. Hardware Providers
The inference providers above abstract away the complexity of managing the underlying hardware. For many large AI companies, it makes sense to manage their own hardware. This includes infrastructure setup (installation, data center buildouts, or colocation setup), model optimization, performance monitoring, and ongoing hardware maintenance.
We can see the hardware providers in the chip section of the value chain:

If it’s true that 40% of Nvidia’s data center revenue comes from inference, then Nvidia dominates this market today. As Jensen pointed out, companies who already own leading-edge hardware for training may transition that to inference hardware as they upgrade equipment.
AMD is providing competition in this space, expecting to generate $5B in annual revenue from their AI Accelerators. Most of the qualitative commentary from their most recent earnings call pointed to inference workloads.
RunPod published an interesting comparison between the H100 and the MI300X on inference, pointing out that the MI300X has better throughput at high batch sizes due to its larger VRAM.
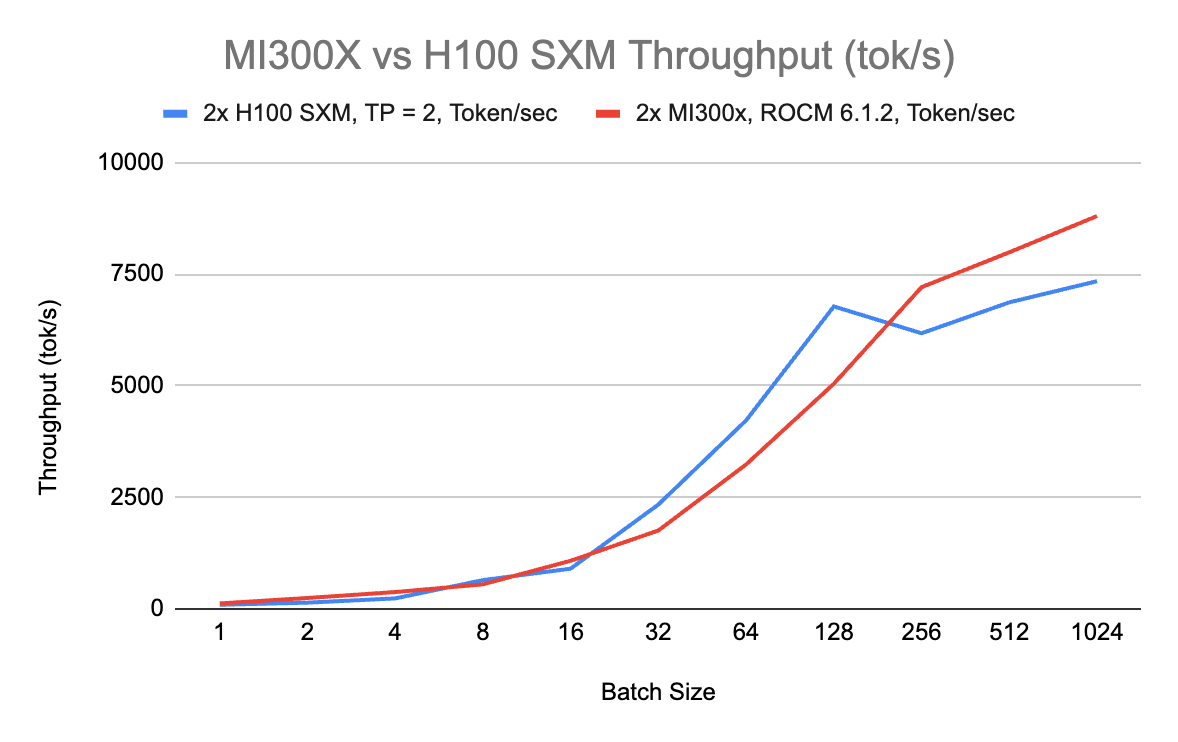
The MI300X is more cost-advantageous at very small and very large batch sizes. As pointed out, pure performance is only one part of the equation. Nvidia’s networking and software lead give it an additional advantage in real-world scenarios requiring systems-level designs.
Then, we have several hardware startups, who have raised a lot of money to capture a piece of this market:

Again, the equation for buyers will be TCO/performance. Value will flow to the hardware level, the question is how much value is created at the layers above the hardware level.
There’s one other variable to the market that’s unclear but can determine a large part of value accretion in inference.
5. What about Inference at the Edge?
Austin from Chipstrat has done some excellent work on this front, and this section repeatedly references it; you should subscribe if you haven’t yet.
As Austin describes, inference at the edge is a win for all parties involved:
Companies will increasingly be motivated to offload these workloads to the consumer’s devices as much as possible — consumers provide the hardware and electricity for companies to generate intelligence.
It’s win-win: Companies reduce CapEx and OpEx, while consumers get the benefits of local inference. It should be noted that adoption of local inference requires
Incentives for consumers (business models that reward local inference, security benefits, etc).
Useful small models that can fit on edge devices.
The former seems straightforward. Models like o1-mini make the latter approach increasingly realistic. I don't need Siri to be a compressed version of the entire web—just a reasoning tool that can manage simple tasks. What’s needed is more of a well-trained 5th grader than a PhD polymath.
The question comes down to developing the hardware and software to meet users needs. I’m confident we can solve those problems over time.

Companies are already developing the hardware, see Apple’s Neural Engines, AMD’s NPU, Intel’s NPU, Qualcomm’s NPU, Google’s Tensor, and startups like Hailo. As small models improve, it will increasingly enable inference at the edge.
My thoughts on inference at the edge:
If we look at the history of disruption, it occurs when a new product offers less functionality at a much lower price that an incumbent can’t compete with. Mainframes gave way to minicomputers, minicomputers gave way to PCs, and PCs gave way to smartphones.
The key variable that opened the door for those disruptions was an oversupply of performance. Top-end solutions solved problems that most people didn’t have. Many computing disruptions came from decentralizing computing because consumers didn’t need the extra performance.
With AI, I don’t see that oversupply of performance yet. ChatGPT is good, but it’s not great yet. Once it becomes great, then the door is opened for AI at the edge. Small language models and NPUs will usher in that era. The question then becomes when, not if, AI happens at the edge.
This market again comes down to the application, and inference at the edge makes far more sense for consumer applications.
6. The Market Moving Forward
Inference workloads will ultimately follow the size and shape of AI applications.
The scale and intensity of AI applications will be the determining factor in the size of the inference market (i.e. how many apps are in use and how complex they are). The shape of those applications (i.e, who is building them) will help determine the shape of the inference market.
If the AI application market ends up heavily concentrated in the hands of a few players in OpenAI, Microsoft, and Google, then inference value will flow to the hardware underlying these vertically integrated companies.
If the AI application market ends up fragmented, with many companies owning smaller pieces of the market, inference is more up for grabs. These smaller, non-vertically-integrated companies, will pay for the managed services of inference providers. Some may want more personalization or customization options than a simple API can provide.
If these applications can utilize simple enough models to run on edge, then this opens the door for inference hardware at the edge.
Finally, all of these variables are spectrums, and not binary. Some amount of inference will be run on the edge, some amount of apps will be highly complex reasoning machines, some amount of apps will be owned by large model providers, and some will be won by startups.
As always, thanks for reading!
Disclaimer: The information contained in this article is not investment advice and should not be used as such. Investors should do their own due diligence before investing in any securities discussed in this article. While I strive for accuracy, I can’t guarantee the accuracy or reliability of this information. This article is based on my opinions and should be considered as such, not a point of fact. Views expressed in posts and other content linked on this website or posted to social media and other platforms are my own and are not the views of Felicis Ventures Management Company, LLC.
Fantastic read!
Fantastic overview. Thanks for putting this together.
Recommending this newsletter