
The Unstructured Data Landscape
Some thoughts on the infrastructure of a new wave of applications (robotics, autonomy, agents).

For those of you who have been reading Generative Value since the beginning (first, I apologize for putting you through those early articles), but secondly, the majority of my early articles were on the data industry!
Data has been an excellent place for both investors and founders alike. From big tech to little tech (early-stage start-ups) to data platforms like Snowflake & Databricks (medium tech?), companies have sold tens of billions of dollars worth of data products to fuel software’s rise.
The one glaring gap in my portfolio of data articles (data industry, data warehouses, databases, and data lakehouses) is the unstructured data landscape. Well, we’re going to fix that today.
And what better timing! Jensen said last week,“the ChatGPT moment for general robotics is just around the corner.” Nvidia released Cosmos, their physical world model. SpaceX continues it’s rapid ascent, creating more and more geospatial data. Autonomous cars and vehicles continue to get us closer to autonomy.
If that’s not enough, the new wave of AI applications is built on unstructured data! It also seems to be the last frontier as textual data is tapped out. Ilya told us that “We’ve achieved peak data and there will be no more.”
Summarized, my thoughts are as follows:
We’ll see more and more innovation around unstructured data to enable the efficient processing of large amounts of unstructured data.
Value will accrue to the distribution networks of data platforms (more on the catch-22 of open-source later!)
Value will accrue to startups solving very specific problems pertaining to the processing and storage of large-scale unstructured data.
For those interested in more details, this will be a deep dive into the unstructured data ecosystem and where value may accrue with the current wave of AI.
1. A Brief Intro to Unstructured Data
Unstructured data broadly encompasses any data not stored in tabular format in SQL databases. Examples include text, images, audio, video, sensor, and geospatial data.
We can visualize the ecosystem here:
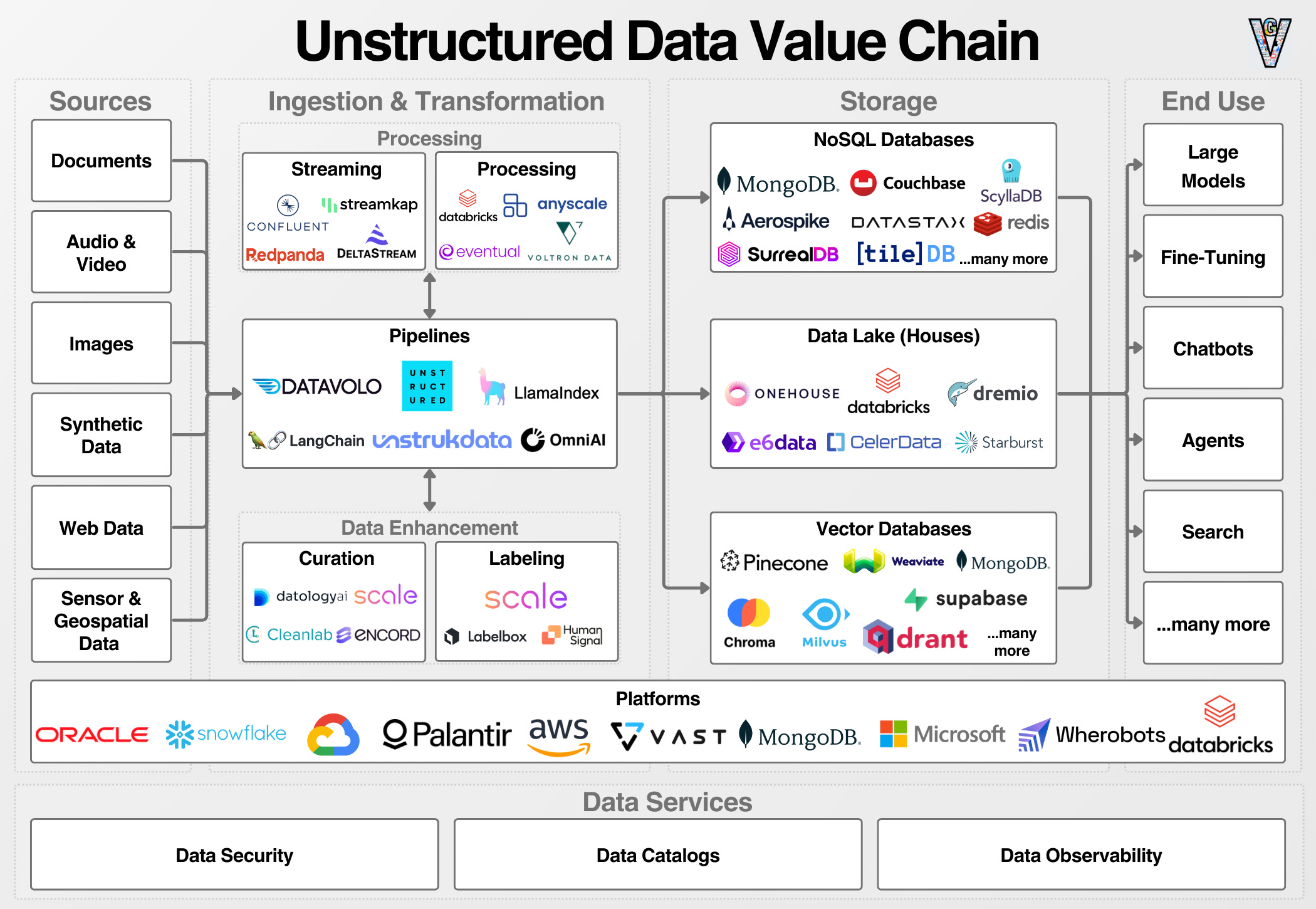
We can broadly break down the market into the following categories:
Sources: Raw data in formats like PDFs, Word docs, emails, audio, and video.
Ingestion: Moving data from source to storage. This includes extracting data from sources, parsing (pulling structured data out of unstructured sources), and loading that data into storage.
Processing & Transformation: Transforming raw data into a state ready for analysis. This can include cleaning, deduplication, filtering, and embedding. For complex or large datasets, compute engines like Spark, Flink, Ray, or Daft will be used. These frameworks provide a more efficient means of executing data operations.
Storage: Storing unstructured data so it can be used. The vast majority of unstructured data is stored in cloud object storage. Data is stored as raw data in objects, with a unique ID pointing to the object. For applications, unstructured data will be stored in a NoSQL or vector database.
End Use: Typical use cases will be some analysis of unstructured data, some application, or retrieval for model training or inference.
Before diving deeper, we should discuss the history of the space, including the development of leaders today like MongoDB and Databricks.
2. An Abridged History of Unstructured Data
Much of this information comes from my series of posts on data, which you can find here. The rise of unstructured data has mostly consisted of three trends:
The consistent exponential growth of unstructured data.
Tools to store that data, i.e., NoSQL databases.
Tools to process large amounts of that data, i.e., Apache Spark.
That rise really started with the internet, so I’ll start there.
The Internet, the Birth of NoSQL, and the Rise of “Big Data”
The internet led to the proliferation of unstructured data. An increasing number of websites and users were creating data, mostly in the form of text; over time, this expanded to video and audio as well. NoSQL databases, like MongoDB and Redis, emerged to handle this type of data over the 2000s.
As the amount of data increased, companies needed a way to process all this data. In 2006, Hadoop was released as an open-source distributed data processing technology (meaning it could process large amounts of data across multiple machines and was free for everyone). This was the first tool to provide a framework for running analytics on “big data.”
The Rise of the Cloud & Apache Spark
Around the same time, AWS released its first product: simple storage service or Amazon S3. S3 provided cheap object storage for unstructured data that could be accessed over the internet. It provided essentially “unlimited” data storage.
In the late 2000s, Spark was created by a team out of UC Berkeley (who would go on to found Databricks in 2013). Spark provided an alternative data processing framework to Hadoop and quickly gained traction in the data science community for training machine learning models, querying big data, and processing real-time data with Spark Streaming.
Compared to Hadoop, the combination of Spark for data processing and Amazon S3 for storage led to a cheaper and more performant combination for managing big data.
By the end of the 2010s, MongoDB and the hyperscalers offered the most popular NoSQL databases for applications. For big data, companies typically used a combination of a data lake for storage and Apache Spark for processing.
Data Platforms & The Rise of AI
The biggest trend in data over the last few years has been the rise of platforms in the industry. Starting with the emergence of the data lakehouse (heavily marketed by Databricks), the largest data platforms expanded to encompass as much of the data landscape as possible.
In the last two years, data companies have focused on AI. Unstructured data management has been around since the 90s. So, what’s new about data infrastructure for AI?
The most important difference is the performance requirements necessitated by AI. The sheer scale of data used to train models has created the need for tooling to process that data as efficiently as possible. Ergo, the rise of AI data infrastructure.
3. An Overview of Unstructured Data Markets
The data market today is dominated by platforms, and that trend is continuing. I think about the data market in three tiers
The hyperscalers
Data Platforms
Startups solving specific problems in the ecosystem.
The Hyperscalers and Data Platforms
In many ways, “unstructured data” is just becoming “data” as every major data platform is expanding support for it.
The data industry is in an interesting position where the large data platforms are expanding to cover the entire data stack. These companies include GCP, AWS, Azure, Palantir, Snowflake, VAST, Oracle, and Databricks, among a few others. This dynamic makes it increasingly challenging to build standalone companies in the space but also increases the chance of acquisitions. More on this in the final section.
NoSQL Databases and MongoDB
I want to specifically call out Mongo and the NoSQL database ecosystem. This is traditionally the primary category focused on unstructured data. MongoDB is the largest standalone company focused on unstructured data. MongoDB’s growth has been remarkably consistent over the last decade:

MongoDB’s broader vision is as an application development platform. They want to be the best platform for building applications with unstructured data. We can also visualize some of the other types of NoSQL databases and providers here:

3a. What’s new with AI?
I’m seeing three primary areas of innovation (as I see it) for unstructured data:
High-Performance Computing Infrastructure
New Storage Use Cases
Unstructured Data Ingestion, Processing, and Transformation
For a deeper dive into the startup ecosystem, check out my colleague Astasia’s post on this problem. Three good stats from that article:
Gartner estimates that about 80-90% of all new data generated is unstructured.
IDC predicts the global volume of data will reach 175 zettabytes by 2025, and much of this will be unstructured.
Today only half of an organization’s unstructured data is analyzed to extract value, and only 58% of unstructured data is ever reused more than once after its initial use. This will dramatically change.
HPC Infrastructure
For the most intensive compute workloads, the goal of data infrastructure is to process as much data as efficiently as possible. Scale AI, for example, was recently valued at $13.8B and hit “nearly $1B” in annualized revenue. They provide a platform to get data “AI-ready” through labeling, curation, and RLHF.
VAST Data, a data storage platform designed for AI workloads, hit a $200M annualized run rate in 2023 and raised at a $9.1B valuation. VAST’s proposition is relatively simple: provide the fastest data storage and processing platform on the market. Another example is a company called DatologyAI, founded by a team out of Meta to provide automated data curation for model training.
New Storage Use Cases
For AI applications, we’ve seen the rise of vector databases, which store unstructured data as numeric values called embeddings, which are mapped based on their meaning. This allows AI models, particularly LLMs, to retrieve data based on semantic similarity rather than exact matches, enabling them to understand nuanced relationships like “wolf” being similar to “dog.”
Vector databases have grown in popularity due to their ability to personalize LLMs. A company can store its custom data as embeddings in vector databases that can be retrieved for personalized experiences. AI agents also leverage this architecture.
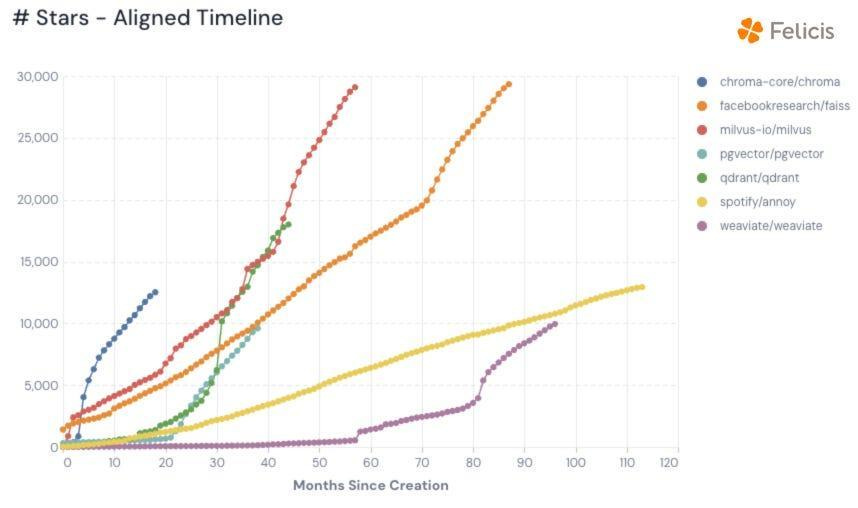
Vector databases come in two forms:
Native vector databases that are purpose-built. Examples being Pinecone, Weaviate, Chroma, Milvus, and Qdrant.
Existing databases have been augmented with vector support. Examples being vector offerings from MongoDB, Supabase, Snowflake, Databricks, and the hyperscalers.
Needless to say, the market’s crowded, and the question comes down to execution.
Ingestion & Transformation
Similar to how Hadoop and Spark rose in the age of the internet and the cloud, we’re seeing the need for increasingly capable tooling for large amounts of unstructured data processing.
This has come in three forms:
Unstructured data pipelines take unstructured data, transform it into a usable format, and move it to a final destination. Examples include Unstructured.io, LlamaIndex, and LangChain.
Data processing engines to run large-scale operations on data. Spark is still the default general-purpose data processing framework, Flink is popular for streaming data, Ray is popular for AI/ML workloads, and Daft is a new framework for this process.
Streaming data frameworks to provide real-time data to applications. Confluent is the largest player in the space and has recently been acquisitive to keep it that way.
Onto arguably the most important question in the space: what does the future of data look like?
4. What does the future of data look like?
If I were to summarize the model of successful companies in the space, it would be data platforms built on open source that ~rapidly~ release new features.
I see three trends driving the future of data:
1. The Expansion of Open-Source
Open source has become the default in the data industry; more than any other asset, users want to have complete control over their data.
Companies like MongoDB and Databricks built massive companies on open-source technology. However, when they did it, there weren’t other data platforms at the time offering a full suite of open-source data solutions. That’s different today.
If a company releases an open-source project, and it does very well, then the large data platforms in Databricks, AWS, Azure, and GCP will integrate a managed offering into their platforms.
Monetizing open source has always been challenging, and defending those moats is even more challenging. On the bright side, data companies are excited to make acquisitions as they rapidly expand as platforms (See the billion-dollar plus Tabular acquisition).
2. The Continued Rise of Platforms
The story in data over the last several years has been the expansion of platforms. Companies like Databricks, Snowflake, and the hyperscalers have aggressively expanded their offerings to encompass nearly the entire data landscape.
For a company to maintain a standalone business, it must aggressively expand as a platform and develop unbelievable customer experience/obsession. Supabase is a great example here, initially offering an open-source Firebase alternative but now has expanded to vector search, authentication, collaboration, edge functions, and more. It acts as the entire backend for applications.
See the point above about acquisitions; large data platforms are a double-edged sword for startups. It makes acquisitions more likely but makes the competition more daunting.
3. New Technologies = New Data Needs
With each wave of technology, we’ve needed new data products to support new applications. Today, it’s AI. As new AI workloads emerge, they’ll need new data features to support them. Tomorrow, things like digital worlds and robotics will need new tools (geospatial data management, for example).
New technologies = new problems = new solutions. And so goes the circle of (data?) life.
As always, thanks for reading!
Disclaimer: The information contained in this article is not investment advice and should not be used as such. Investors should do their own due diligence before investing in any securities discussed in this article. While I strive for accuracy, I can’t guarantee the accuracy or reliability of this information. This article is based on my opinions and should be considered as such, not a point of fact. Views expressed in posts and other content linked on this website or posted to social media and other platforms are my own and are not the views of Felicis Ventures Management Company, LLC.
Thanks for this Eric! Super timely - looking at a few companies in this space right now.
Hi Eric,
Thanks for this
What are your thoughts on Salesforce and its Data Cloud, boosted by the recent acquisition of Own, and how it ties into preparing unstructured data for Agentic AI?
Thanks